
🎯학습 목표
1. 이미지가 서비스 성능에 미치는 비용을 이해하고, 이를 줄이기 위해 업로드 시점 최적화(WebP 변환 + 리사이징) 가 왜 필요한지 설명할 수 있습니다.
2. 무제한 업로드를 기술이 아닌 정책(최대 업로드 수 제한) 으로 먼저 제어하고, 원본 1장에서 main/thumb 파생 이미지를 생성하는 설계를 설명할 수 있습니다.
3. Pre-upload(`imageKey` + Redis TTL)를 통해 서버가 이미지 URL을 보증하고, 이후 consume 단계로 도메인과 안전하게 연결하는 구조를 이해할 수 있습니다.
4. 이미지 포맷 선택을 압축률이 아닌 운영 안정성 관점(WebP 선택) 에서 판단하고, 업로드 실패 문제를 애플리케이션 + 인프라(Nginx) 레이어까지 포함해 해결할 수 있습니다.
1. 이미지 최적화를 ‘업로드’ 단계에서 시작하는 이유
모임 플랫폼 서비스에서 핵심 기능 중 한 가지인 이미지입니다. 특히,모임 목록 조회 또는 상세 조회는 가장 빈번하게 조회되는 API로 요청과 응답에서 큰 비용이 발생되는 이미지는 반드시 최적화가 필요한 영역입니다. 구체적으로, 웹 브라우저에서 이미지가 포함된 컨텐츠들을 조회하는 순간, 아래의 비용을 동시에 만들어냅니다.
- 네트워크 비용: 파일이 크면 클수록 다운로드 시간이 길어지고 트래픽 요금도 늘어납니다.
- 렌더링 비용: 브라우저가 큰 이미지를 디코딩하고 리사이징하는 데 CPU, Memory를 사용합니다.
- 사용자 체감 성능: 특히 목록 화면(썸네일)에서 이미지가 늦게 뜨면 “사이트가 느리다”는 인상이 강해집니다.
이미지 비용을 인지한 상태에서 “원본을 그대로 저장하고 필요할 때마다 줄여서 쓰자”는 방식은, 생각보다 문제가 많습니다.
1. 클라이언트/브라우저 리사이징은 ‘전송량’을 줄이지 못합니다
예를 들어 3000x2000 크기의 이미지 파일을 내려받고, 화면에서 100x100으로 줄여 보인다고 해도 전송은 이미 3000x2000짜리를 받은 뒤입니다. 즉, 브라우저 리사이징은 “보이는 크기”만 줄일 뿐, 네트워크 비용은 그대로 지불한 상태입니다. 구체적으로, Amazon S3 안에 저장된 3000x2000 크기의 이미지를 가져와서 100x100으로 변환할 때 이미 비용이 발생해요.😢
2. 목록, 썸네일 화면은 ‘작은 이미지’가 가장 많이 필요합니다
모임 목록, 검색 결과, 카드 UI 같은 화면은 썸네일이 많습니다. 여기서 원본을 내려받으면 병목이 생기기 쉽습니다. 그래서 이번 구현은 방향을 이렇게 잡습니다. “업로드 순간에 용도별 최적 크기, 포맷으로 변환해 두고, 이후 화면에서는 그 결과물을 바로 쓰게 하자.”
2. 이미지 선 업로드 구조
이번 구조의 핵심은 단순히 “이미지를 최적화해서 S3에 올린다”에서 끝나지 않습니다.
Pre-upload를 두는 이유는 크게 트랜잭션, 보안 및 정합성, 운영과 비용 3가지 관점에서 설명할 수 있습니다.
2.1 트랜잭션 관점: 느린 작업(이미지 처리)을 도메인 작업(그룹 생성)에서 분리
모임 생성, 수정은 보통 DB 트랜잭션 안에서 수행하는 작업입니다. 그런데 이미지 업로드는 성격이 완전히 다릅니다.
- 파일 변환(WebP, 리사이징) → CPU 비용 발생
- Amazon S3 업로드 → 외부 네트워크 + 실패 가능성
- 용량 및 형식 문제 → 예외 발생 가능성이 높은 지점
이걸 모임 생성 요청 하나에 다 넣으면 어떤 일이 생길까요?
- 모임 정보는 저장됐는데 이미지 업로드가 실패 → 정합성 문제가 생깁니다.
- 이미지 업로드가 늦어지면 모임 생성 API가 불필요하게 느려집니다.
- 재시도와 롤백 설계가 정말 매우 복잡해집니다.
따라서 이번 구조는 “실패 가능성이 높은 느린 작업”을 먼저 분리합니다.
분리는 크게 두 단계로 이미지 업로드는 먼저(Pre-upload)하고, 모임 생성과 수정을 수행합니다.
2.2 보안 및 정합성 관점: 클라이언트가 임의 URL을 주입하지 못하게
이미지를 모임에 연결할 때, 클라이언트가 요청 바디에 이런 식으로 보낼 수도 있습니다.
- “이 URL을 모임 이미지로 저장해 주세요”
- 그런데 그 URL이 정말 이 사용자가 업로드한 이미지인지 서버는 확신할 수 없습니다.
- 심지어 외부 URL을 넣어서 악성 컨텐츠를 노출시키는 식의 문제가 생길 수도 있습니다.
그래서 이번 구현에서 클라이언트가 URL을 최종 데이터로 제출하지 않게 합니다.
- 서버가 발급한
imageKey(UUID)를 기준으로 - 서버가 보증하는 URL 세트를 Redis에 저장하고
- 나중에 그룹 생성/수정 시에는
imageKey만 받아서 서버가 최종 매핑
이렇게 하면 “이미지 연결의 주도권”이 서버에 남아 정합성이 강해집니다.
2.3 운영과 비용 관점: 업로드만 하고 사용되지 않는 이미지를 자동 정리
사용자가 이미지 업로드는 했는데, 그룹 생성, 수정 화면에서 이탈하는 경우가 있습니다. 그럼 S3에는 “어디에도 연결되지 않은 이미지”가 남습니다. 이게 쌓이고, 쌓이다보면 스토리지 비용 증가하고, 관리 대상 증가하고, 운영 난이도 증가하게 됩니다. 먼 훗날, S3 안에 저장된 이미지들이 어느 모임 또는 회원에 등록된 이미지인지 여부를 판단하고 정리하는 작업을 수행해야 한다고 생각해보면 벌써 복잡하고 꽤 큰 작업이라는 것을 알 수 있습니다.
그래서 Redis에서 Pre-upload를 TTL(2시간)로 관리하면 업로드 이후 일정 시간 안에 확정되지 않으면 자동 만료할 수 있습니다. 덕분에 사용되지 않은 이미지가 계속 남는 상황을 줄일 수 있습니다. 이 TTL은 다음 단계에서 Redis 저장 코드를 보면서 더 구체적으로 정리하겠습니다.
3. 이미지 선 업로드 API

항상 모임 생성과 수정에서 먼저 호출되는 위 API는 “모임 이미지를 최종 확정하는 API”가 아니라, 모임 생성과 수정에 필요한 이미지 선 업로드 API입니다. 그래서 이 컨트롤러는 어떤 책임을 지게 될까요? 바로 이미지 최적화와 안전한 연결 준비를 수행합니다.
- 클라이언트로부터 이미지를 받는다.
- 서버에서 정한 기준에 따라 최적화된 Main, Thumbnail 크기의 이미지를 Webp 포멧으로 생성한다.
imageKey를 발급하고, 해당 키에 대응되는 URL 세트를 서버가 Redis에 저장한다.- 모임 생성과 수정에서 바로 사용할 수 있는 "이미 준비된 상태"로 반환한다.
이때 오해하면 안되는 것은 모임과 모임 이미지 엔티티 간의 관계를 저장하지 않고, 최종 이미지를 확정하지 않습니다. 여기에서 반드시 정리하고 넘어가고 싶은 것은, 이미지 최적화는 “압축”만이 아니라, 업로드 파이프라인의 책임 분리와 정합성 보증까지 포함하는 설계 문제로 받아들이고 다음과 같이 책임을 갖도록 구현했습니다.
- 업로드 시점 최적화(WebP + 리사이징)로 전송량/렌더링 비용 감소
- Pre-upload(imageKey + Redis TTL)로 서버가 이미지 연결을 보증
- 모임 생성과 수정 도메인 로직에서 이미지 처리 부담을 분리한 구조
3.1 정책부터 먼저 제한: 최대 3장을 기술이 아니라 규칙으로 막기
이미지 최적화를 잘 해도, 클라이언트가 무제한으로 이미지를 업로드하면 결국 비용이 폭발합니다. 그래서 이 구조는 최적화보다 먼저 정책(제한)으로 문제 범위를 줄였습니다. 모임에서 제공되는 실제 이미지는 최대 3장이기 때문에 업로드가 가능한 이미지 개수 또한 3장으로 제한하도록 정책을 정했습니다.

최대 이미지 업로드 수 제한으 정책으로 해결하면서 다음과 같은 부분에서 부담을 크게 줄일 수 있게 됩니다.
- 네트워크 트래픽
- S3 저장 비용
- 변환 CPU 비용
- Redis 저장량
3.2 업로드 즉시 최적화: 원본 1장 → main/thumb 2장 파생 생성
모임 생성과 수정에서 선 업로드 이미지는 440x240, 100x100 크기의 두 개 이미지로 변환됩니다.


- main(440x240): 모임 대표 이미지, 카드/상세 상단 등 “큰 영역”용
- thumb(100x100): 목록, 검색 결과, 작은 카드 UI 같은 “대량 노출”용
여기서 포인트는, “단순 압축”이 아니라 용도별 파생 이미지를 서버가 책임지고 만든다는 구조입니다. 이렇게 하면 클라이언트는 화면에서 “원본을 내려받아 줄여 쓰는” 비효율을 반복하지 않게 됩니다. 덕분에 목록 화면에서는 처음부터 100x100 webp 파일만 내려받기 때문에 전송량과 디코딩 비용이 함께 줄어듭니다.
3.3 WebP 변환은 서버에서: content-type/확장자/용량 검증 + 변환 실패 방어
이미지 처리 파트는 서비스(ImageUploadService) 레벨에서 전담하고, 업로드 전에 반드시 검증을 수행합니다.
- 용량 제한:
image.max-size-bytes: 20MB - 허용 타입: jpeg, png, webp
- 허용 확장자: .jpg, .jpeg, .png, .webp
그리고 실제 변환은 Thumbnailator로 진행합니다. 이 설계의 핵심은 단순히 “WebP로 바꾸는 것”이 아니라, 서버가 변환 결과물을 만들어 “브라우저가 받을 파일 자체”를 최적화한다는 점입니다. 따라서 반복적인 이미지 변환 작업을 거치지 않고, 한 번의 작업으로 최적화된 이미지를 응답할 수 있습니다.

3.4 imageKey 발급 + Redis TTL 저장: 서버가 URL 세트를 보증
이제 최적화된 두 URL이 생겼다면, 다음 단계는 “이 이미지들이 앞으로 모임에 연결될 수 있는지”를 서버가 보증해야 합니다. 그래서 imageKey(UUID)를 발급하고, 서버가 그 키에 대한 URL 세트를 Redis에 저장합니다. Redis 쪽은 TTL 2시간으로 관리합니다.
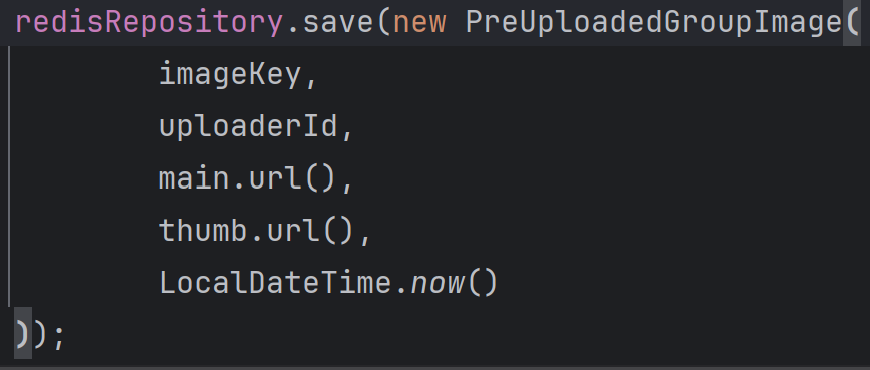

가장 큰 장점은 누가 이미지 업로드를 했는지 imageKey로 검증하고, 어떤 URL 세트를 갖는지 알 수 있습니다. 부가적으로, 다음과 같은 낙수효과를 얻을 수 있습니다.
- 클라이언트가 임의 URL을 주입할 수 없음
- 확정되지 않은 업로드는 TTL로 자연스럽게 만료됨
- 나중에 모임 생성과 수정 단계에서는 imageKey만 받아서 서버가 최종 매핑 가능
3.5 응답 형태: “이미 준비된 상태”로 돌려준다


단순히 “업로드 결과” 여부를 응답하는 것이 아니라, 모임 생성과 수정에서 바로 사용할 수 있는 준비 상태입니다.
클라이언트는 다음 단계(모임 생성과 수정 API 요청)에서 imageKey와 sortOrder만 넘기면 됩니다.
4. Redis Pre-upload 확정(consume) 단계: 이미지와 도메인을 안전하게 연결하기
이미지는 이미 최적화되어 S3에 올라가 있고, 서버는 imageKey를 기준으로 그 URL 세트를 Redis에 임시 보관하고 있습니다.
하지만 이 상태는 아직 "확정"된 상태가 아닙니다. 모임이 실제로 생성되거나 수정되기 전까지, 이 이미지는 어디에도 속하지 않은 임시 자원입니다. 그래서 반드시 모임 생성/수정 시점에 imageKey를 기준으로 이 이미지가 정말로 사용되었는지 확인하고 사용되었다면 Redis에서 소비(consume)하여 확정 상태로 전환해야 합니다. 이것이 바로 제가 구현한 Pre-upload 구조의 마지막 퍼즐입니다.
4.1 동시에 조회와 삭제를 수행하자 consume!
Redis에 단순히 find()만 하고 끝내면 아래 세 개의 문제에 반드시 부딪히게 됩니다.
- 같은
imageKey를 여러 번 재사용할 수 있음 - 한 번 사용된 이미지가 또 다른 모임에 연결될 수 있음
- “이미 확정된 이미지인지” 여부를 서버가 구분할 수 없음
즉, 정합성이 깨집니다. 그래서 Redis 조회는 단순 조회가 아니라, “조회 + 삭제”를 동시에 수행하는 consume 방식을 사용합니다.

consume 메서드는 다음과 같은 중요한 성질을 가집니다.
- 한 번 가져오면 Redis에서 사라짐
- 같은
imageKey는 단 한 번만 확정 가능 - 자연스럽게 중복 연결을 방지
모임 생성과 수정에서의 흐름으로 consume 메서드가 어떻게 동작하는지 살펴보겠습니다.
- 클라이언트는 URL이 아니라
imageKey목록으로 Request - 서버는 각
imageKey에 대해 Redis에서consume - consume에 성공한 경우에만 S3 URL을 꺼내, 그룹 이미지 엔티티로 저장
- consume 실패(없음 또는 만료) → 잘못된 요청으로 처리
이 구조 덕분에 서버는 다음을 보장할 수 있습니다.
- 이 이미지는 서버가 직접 생성한 이미지다
- 이 이미지는 이미 누군가에게 확정되지 않았다
- 이 이미지는 TTL 내에 정상 흐름으로 사용되었다
4.2 TTL + consume 조합이 만들어내는 안정성
Redis TTL(2시간)과 consume 구조가 결합되면, 다음과 같은 시나리오들이 자연스럽게 해결됩니다.
1. 업로드만 하고 이탈한 사용자
- 이미지 업로드 → Redis 저장
- 모임 생성 안 함
- 2시간 후 TTL 만료
- 이미지는 자동으로 “연결 불가 상태”가 됨
(필요하다면, 이후 배치로 S3 정리까지 연결 가능)
2. 이미 사용된 imageKey 재요청
- 첫 모임 생성에서 consume 성공
- Redis에서 삭제됨
- 같은 imageKey로 다시 요청 → consume 실패
- 중복 연결 방지
3. 악의적 요청 또는 클라이언트 버그
- 임의의 URL 전달 불가
- 서버가 발급한 imageKey만 허용
- Redis에 없는 키는 무조건 실패
즉, 이 구조는 보안 로직을 도메인 안으로 자연스럽게 끌어들인 설계라고 볼 수 있습니다.
4.3 이미지 업로드와 모임 도메인 트랜잭션이 만나는 유일한 지점
중요한 설계 포인트 하나를 짚고 넘어가야 합니다.
- 이미지 업로드 API → 느리고 실패 가능성이 높은 작업
- 모임 생성과 수정 API → 트랜잭션 정합성이 중요한 작업
이 둘이 직접 얽히지 않고, Redis consume이라는 단 하나의 연결 지점만 공유합니다. 덕분에, 이미지 처리 실패가 모임 생성 트랜잭션을 오염시키지 않고 모임 생성 실패가 이미지 업로드를 롤백하려고 애쓸 필요도 없어지며 각 레이어의 책임이 명확해집니다.
5. 고아(Orphan) 선업로드 이미지 삭제: TTL만으로는 끝나지 않는 S3 정리
Redis TTL(2시간)과 consume(조회+삭제) 구조 덕분에, 확정되지 않은 imageKey는 자동으로 만료되고 중복 사용도 방지할 수 있습니다. 하지만 여기서 한 가지가 남습니다. 이미지 파일은 이미 업로드 시점에 S3에 올라가 있기 때문에, Redis에서 키가 만료되었다고 해서 S3 객체가 자동으로 지워지지는 않습니다. 즉, 다음 시나리오가 발생할 수 있습니다.
사용자가 선 업로드까지는 했지만 모임 생성/수정 화면에서 이탈하면, Redis에는 TTL로 흔적이 사라지지만 S3에는 어디에도 연결되지 않은 이미지(main/thumb)가 남습니다. 이것이 시간이 지나면 “고아 이미지(orphan image)”가 누적되어 스토리지 비용 증가와 운영 복잡도 증가로 이어집니다. 그래서 저는 “만료된 imageKey를 기준으로 S3 객체까지 정리하는 GC(가비지 컬렉션)”를 추가로 두었습니다.
5.1 Redis 인덱스(ZSET)로 ‘오래된 imageKey’를 빠르게 찾기
선 업로드 시점에 Redis에는 메타데이터(PreUploadedGroupImage)를 저장합니다. 여기서 중요한 건, 메타를 단순히 key-value로만 저장하면 “만료된 것들을 한 번에 찾기”가 어렵다는 점입니다. 그래서 IDX_KEY(group:v2:img:pre:idx)라는 ZSET 인덱스를 함께 두고, score = createdAt epochSecond로 저장해 시간 기준 조회가 가능하게 만들었습니다.
- 메타 저장:
group:v2:img:pre:{imageKey}(TTL: 1일) - 인덱스 저장:
group:v2:img:pre:idx(ZSET, score=생성 시각)
이 인덱스 덕분에 GC 워커는 다음 쿼리로 “오래된 imageKey 후보”를 배치로 가져옵니다.
ZRANGEBYSCORE idx -inf threshold LIMIT 0 limit
즉, “이 시간 이전에 생성된 선 업로드 키들만” 빠르게 후보로 뽑을 수 있습니다.
모임 이미지 선업로드의 응답에서 imageKey는 Redis에서 2시간 동안 보관됩니다. 그래서 현재 시각 - 2시간 이전에 생성된 imageKey만 고아 후보로 정했습니다. 이 유예 시간이 짧으면 정상 플로우 이미지까지 삭제될 수 있고, 너무 길면 고아 이미지가 오래 쌓입니다. 저는 “최대 모임 생성까지 걸릴 수 있는 시간”을 기준으로 1~2시간을 권장 범위로 잡았습니다.
5.2 삭제 워커 동작: 후보 조회 → 메타 확인 → S3 삭제 → Redis 정리


PreUploadedGroupImageOrphanGcWorker는 10분마다 실행되며(@Scheduled(fixedDelay=10min)), 한 번에 너무 많이 삭제하지 않도록 BATCH_LIMIT를 둡니다. 이 워커가 하는 일은 다음과 같습니다.
- 고아 후보 imageKey 목록 조회
- ZSET 인덱스에서
threshold이전 데이터만 limit만큼 가져옵니다.
- ZSET 인덱스에서
- 메타 존재 여부 확인
find(imageKey)로 메타(= S3 URL 세트)를 가져옵니다.- 메타가 없다면: 이미 TTL로 사라진 상태이므로 인덱스만 제거하고 종료합니다.
- S3 객체 삭제
- 메타가 있다면, main/thumb URL을 꺼내
deleteAllByUrls()로 S3 파일을 삭제합니다.
- 메타가 있다면, main/thumb URL을 꺼내
- Redis consume로 최종 정리(조회+삭제) + 인덱스 제거
- 마지막으로
consume(imageKey)를 호출해 메타를 제거하고 인덱스에서도 제거합니다.
- 마지막으로
여기서 중요한 포인트는 “GC는 정합성을 엄격히 증명하는 로직이 아니라, 운영상 남은 찌꺼기를 치우는 로직”이라는 점입니다. 따라서 GC 단계에서는 “이미 누군가 consume했을 수도 있음”을 전제로, 있으면 지우고 없으면 정리만 한다는 수준이면 충분하다고 판단했습니다.
5.3 실패한 건 인덱스를 남겨 ‘다음 주기 재시도’로 처리
S3 삭제는 외부 네트워크 작업이라 실패할 수 있습니다. DB 트랜잭션처럼 롤백이 되지 않기 때문에, 실패했을 때 가장 중요한 건 “재시도 가능하게 남겨두는 것”입니다. 그래서 워커는 예외가 나면 인덱스를 지우지 않고 그대로 두고, 로그만 남깁니다. 다음 스케줄 주기에 다시 후보로 잡혀 재시도됩니다.
- 성공: S3 삭제 + consume + index 제거
- 메타 없음: index만 제거
- 실패: index 유지(재시도)
이 방식은 “최소 변경”으로도 운영 안정성을 확보할 수 있고, 이후 트래픽이 커지면 outbox나 별도 잡 큐로 확장하기도 쉽다는 것을 파악하고 현행을 유지했습니다. Redis TTL + consume이 “연결 정합성”을 책임진다면, Orphan GC 워커는 S3에 남는 파일을 정리해 “운영 비용”까지 마무리하는 장치입니다.
6. 이미지 최적화 포맷 선택: 왜 AVIF가 아니라 WebP 선택한 이유
이미지 최적화를 이야기하면 자연스럽게 이런 질문이 따라옵니다. “압축률이 더 좋은 AVIF를 쓰는 게 맞지 않나요?”
실제로 동일한 원본 이미지를 기준으로 비교해보면 결과는 꽤 극단적입니다.

- JPEG 대비
- WebP: 약 70~75% 용량 감소
- AVIF: 약 90% 이상 용량 감소
숫자만 보면 AVIF가 압도적입니다. 그럼에도 이번 구현에서는 WebP를 기본 포맷으로 선택했습니다.
이 결정은 “최대 압축률”이 아니라 안정적인 서비스 운영을 기준으로 한 선택이었습니다.
6.1 브라우저 및 플랫폼 호환성
WebP는 현재 기준으로 사실상 표준에 가까운 이미지 포맷입니다.
- Chrome, Edge, Firefox, Safari(모바일 포함) 안정 지원
- 모바일 WebView, 인앱 브라우저 환경에서도 이슈 발생 가능성 낮음
서비스 특성상 “특정 브라우저에서만 이미지가 안 보이는 문제”는 단 한 번만 발생해도 사용자 신뢰를 크게 깎아먹습니다. 모든 사용자에게 동일한 이미지 경험을 제공하는 것이 몇 %의 추가 압축률보다 더 중요하다고 판단했습니다.
6.2 서버 사이드 변환 안정성 (Java 생태계 기준)
이번 구조에서는 이미지 변환을 서버 업로드 파이프라인에서 직접 수행합니다. 즉, 프론트가 아니라 백엔드에서 포맷 변환 책임을 집니다. 이때 중요한 건 “이론적인 압축률”이 아니라, 라이브러리 성숙도, 예외 발생 빈도, 장애 시 영향 범위입니다. Java 환경에서 Thumbnailator, ImageIO 등을 활용한 WebP 변환은 이미 충분히 검증된 케이스가 많고, 실패 패턴도 예측 가능합니다. 반면 AVIF는 인코딩 라이브러리 의존성이 높고, 변환 속도 편차가 크며 실패 케이스 대응이 까다롭습니다. 이미지 변환 실패가 곧바로 업로드 실패 → 사용자 이탈로 이어질 수 있기 때문에, 이번 단계에서는 안정성을 우선했습니다.
지금은 WebP, 필요해지면 AVIF" 전략을 선택했습니다. 그래서 “AVIF를 영원히 쓰지 않겠다”는 의미는 아닙니다. 트래픽이 더 커지고, 이미지 비중이 더 높아지고, CDN + fallback 전략을 도입할 여지가 생기면AVIF를 점진적으로 도입할 수 있는 여지는 충분히 열어둔 상태입니다. 다만 초기 구조에서는, “최대 압축”보다 “실패하지 않는 업로드 파이프라인”* 이 더 중요하다고 판단했습니다.
7. Backend 구현 중 겪은 문제: Nginx 업로드 제한 트러블슈팅
이미지 업로드 정책을 서버에 잘 적용했음에도, 프론트엔드에서 업로드가 실패하는 문제가 발생했습니다.
- 프론트에서 업로드 시 실패
- 서버 로그 또는 응답에서 413 Request Entity Too Large
처음엔 자연스럽게 Spring Boot 설정을 의심하게 됩니다.
7.1 Spring Boot 설정은 이미 적용되어 있었다
spring:
servlet:
multipart:
max-file-size: 20MB
max-request-size: 20MB
image:
max-size-bytes: 20971520 # 20MB
max-width: 7000
max-height: 7000- 파일 크기 제한: 최대 20MB
- 해상도 제한: 최대 7000 × 7000
로컬 환경에서 테스트해보면 문제없이 업로드 성공합니다.
즉, 애플리케이션 레벨 설정에는 문제가 없었습니다.
7.2 진짜 원인은 Nginx 앞단 제한
이 시점에서 의심해야 할 것은 애플리케이션 앞단의 인프라 레이어입니다. 바로 Nginx입니다. Nginx는 기본적으로 요청 본문 크기를 제한합니다. 이 제한에 걸리면, Spring Boot까지 요청이 도달하지도 않습니다. 그래서 Nginx 설정을 확인했고, 아래 설정을 추가했습니다.
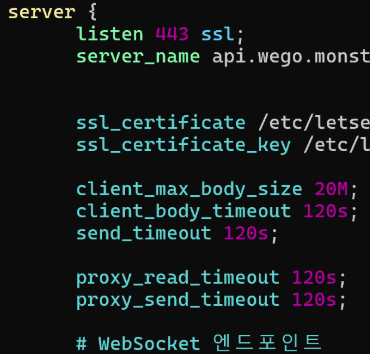
client_max_body_size 20M; # 업로드 포함 요청 본문 최대 크기
client_body_timeout 120s; # 느린 업로드 보호
send_timeout 120s; # 응답 지연 보호
proxy_read_timeout 120s; # 백엔드 응답 대기 시간
proxy_send_timeout 120s; # 요청 전달 지연 허용이후 동일한 요청을 다시 시도했을 때, 업로드가 정상적으로 수행되는 것을 확인했습니다.
이 문제를 통해 다시 한 번 명확해진 사실은 “Spring Boot 설정만으로는 업로드 정책이 완성되지 않는다.”입니다.
- 클라이언트
- Nginx
- 애플리케이션 서버
이 세 레이어의 정책이 모두 일치해야 사용자가 체감하는 “업로드 성공”이 만들어집니다. 특히 이미지 업로드처럼 요청 바디가 큰 작업은 가장 앞단(Nginx) 에서 막히는 경우가 매우 흔하다는 사실도 알게 되었습니다. 이미지 최적화를 하면서 이미지 포맷 선택은 “압축률 경쟁”이 아니라 운영 안정성의 문제 관점에서 바라볼 줄 알아야 한다는 것을 느꼈습니다. 트러블슈팅의 핵심 내용을 정리하면서 이미지 최적화 개선 내용 글을 마무리하겠습니다.
- WebP는 현재 서비스 단계에서 가장 안전한 선택
- 업로드 실패 이슈는 애플리케이션보다 인프라 설정을 먼저 의심해야 함
- 이미지 최적화는 코드뿐 아니라 배포 환경까지 포함한 설계 문제
'💭Retrospective' 카테고리의 다른 글
| CORS: 프론트엔드 로컬 환경에서 터진 CORS 해결하기 (0) | 2026.01.18 |
|---|---|
| 모임 참가 신청 API: 모임 최대 참가자 수 동시성 문제 해결하기 (0) | 2026.01.10 |
| 서평단: 그림으로 이해하는 도커와 쿠버네티스 (0) | 2026.01.09 |
| 서평단: Do it! HTML+CSS 웹 표준의 정석 탄탄한 웹 기본기를 위한 교과서 | 개정판 3 판 (0) | 2025.12.17 |
| 모임 목록 조회 API 트러블슈팅: 커서 기반 페이징과 N+1을 설계 구조로 해결하기 (0) | 2025.12.16 |