
1. Redisson으로 분산 락 구현하기
앞에서 Spring Data Redis만으로 분산 락을 직접 구현할 때 마주치는 수많은 예외 상황(락 소유자 검증, TTL 관리, 원자적 락 해제 등)을 살펴보았다. 결론은 하나다.
"직접 완벽하게 짜는 것은 생각보다 매우 어렵고 위험하다."
Redisson은 바로 이러한 번거롭고 복잡한 분산 시스템의 동시성 문제들을 단 몇 줄의 코드로 우아하게 해결하기 위해 등장한 라이브러리다.
1.1 Redisson의 핵심 객체: `RLock`
Redisson에서 분산 락은 RLock이라는 객체로 추상화되어 제공된다.
RLock lock = redissonClient.getLock("lock:product:1");
개발자는 이 코드 한 줄만으로 Redis에 `lock:product:1`이라는 이름의 분산 락 객체를 선언하고 다룰 수 있게 된다. 가장 단순한 형태의 락 획득 코드를 보자.
RLock lock = redissonClient.getLock("lock:product:1");
lock.lock(); // 락 획득할 때까지 무한 대기
try {
Product product = productRepository.findById(id).orElseThrow();
product.decrease(quantity);
} finally {
lock.unlock(); // 안전한 락 해제
}
언뜻 보면 자바 표준 동시성 도구인 ReentrantLock과 사용법이 매우 비슷하다. 하지만 실제 내부적으로는 여러 서버(서버 A, B, C)가 동시에 요청을 보내더라도, Redis를 거쳐 철저하게 동시에 단 하나의 요청만 진입할 수 있도록 통제하는 강력한 분산 락 메커니즘이 작동한다.
무한 대기 방지를 위한 tryLock() 활용하기
위의 lock.lock()은 락을 획득할 때까지 스레드가 무한정 대기(Block)하므로 실무 웹 서비스에서는 위험할 수 있다. 앞서 가던 작업이 멈추면 뒤의 요청들이 줄줄이 대기하며 서버가 마비되기 때문이다. 그래서 실무에서는 일정 시간만 기다려보고 안 되면 포기하는 tryLock()을 훨씬 더 많이 사용한다.
// 락 획득을 최대 5초 동안 시도하고, 획득하면 10초간 유지한다.
boolean acquired = lock.tryLock(5, 10, TimeUnit.SECONDS);
이 메서드에 들어가는 세 가지 인자의 의미를 명확히 정리해 보자.
- `waitTime (5)`: 락 획득을 위해 대기할 최대 시간.
락을 쥔 선행 작업이 5초 안에 끝나서 락을 반납하면 바로 진입하지만, 5초가 지나도 락이 안 풀리면 `false`를 반환하며 포기한다. - `leaseTime (10)`: 락을 획득한 후 만료 제거될 시간(TTL).
락을 성공적으로 획득한 후, 최대 10초가 지나면 락이 자동으로 해제된다. - `TimeUnit`: 앞선 시간의 단위 (여기서는 초 단위인 SECONDS)
Redisson은 어떻게 대기 부하를 줄일까?
Spring Data Redis로 구현한 재시도 로직은 주기적으로 Redis에 락을 달라고 징징대는 스핀 락(Spin Lock) 구조였다.
반면 Redisson은 Redis의 Pub/Sub(발행/구독) 기능을 활용한다. 락이 풀리면 Redis가 대기 중인 서버들에게 "이제 락 풀렸으니 가져가세요!" 하고 신호를 보내기 때문에, 대기 시간 동안 Redis 서버에 부하를 거의 주지 않는다.
1.2 락 조기 만료 문제를 해결하는 구원투수: Watch Dog
앞서 3장에서 가장 큰 골칫거리로 꼽았던 문제가 있었다. 바로 "내가 설정한 락의 TTL(만료 시간)보다 실제 비즈니스 로직 처리 시간이 더 길어질 때" 락이 도중에 풀려버리는 끔찍한 상황이다. Redisson은 이를 Watch Dog(감시견)이라는 기능으로 완벽하게 해결했다.
// leaseTime을 지정하지 않고 락을 건다.
lock.lock();
// 또는
lock.tryLock(5, -1, TimeUnit.SECONDS);
이처럼 leaseTime을 주지 않거나 `-1`로 설정하면, Redisson은 내부적으로 Watch Dog 메커니즘을 활성화한다. Watch Dog의 역할은 매우 단순하고 강력하다. 락의 기본 만료 시간(기본값 `30`초)을 적용해 둔 뒤 background 스레드에서 락을 보유한 내 스레드가 아직 살아있는지 계속 감시한다. 그리고 작업이 끝나지 않았다면 락의 만료 시간을 주기적으로 자동 연장(갱신)해 준다. 결과적으로 개발자는 백엔드 로직의 수행 시간이 인프라 상황에 따라 1초가 걸리든, 5초가 걸리든 "TTL을 몇 초로 잡아야 안전하지?"에 대한 딜레마에서 완전히 해방된다. 작업이 안전하게 최종 종료되어 unlock()이 호출되는 순간 비로소 락은 깔끔하게 지워진다.
⚠️ 실무 주의: leaseTime을 명시하면 Watch Dog은 작동하지 않는다!
많은 실수 구간이다.`lock.tryLock(3, 5, TimeUnit.SECONDS)` 처럼 습관적으로 락 유지 시간(5초)을 명시해 두고, "왜 작업이 길어졌는데 Watch Dog이 만료 시간을 연장 안 해주지?" 하며 삽질을 하곤 한다. 유지 시간을 명시하는 순간 Watch Dog 기능은 꺼지므로, 만료 시간 자동 연장 기능이 필요하다면 반드시 유지 시간을 비워두어야(`-1`) 한다.
락 소유자 검증 문제도 자동 해결
Spring Data Redis로 직접 짰을 때는 A가 작업이 늦어져 만료된 락을 뒤늦게 delete 하다가, 새로 들어온 B의 락을 지워버리는 치명적인 버그가 있었다. 하지만 Redisson은 내부적으로 락을 생성할 때 [어떤 서버의 : 어떤 스레드(Thread ID)]가 이 락을 쥐고 있는지 식별 정보까지 함께 저장하여 관리한다. 따라서 lock.unlock()이 실행될 때 자동으로 "지금 이 락을 지우려는 주체와 락의 주인이 일치하는지" 검증하기 때문에, 남이 건 락을 실수로 삭제하는 사고가 구조적으로 불가능하다.
1.3 결론: Redisson이 우리에게 준 선물
Spring Data Redis로 직접 분산 락을 구현하려고 했다면 우리는 아래의 체크리스트를 하나하나 다 코드로 방어해야 했을 것이다.
- 락 해제 시 내가 건 락이 맞는지 UUID 검증 로직 구현
- 검증과 해제가 찰나의 순간에 꼬이지 않도록 원자성을 보장하는 Lua Script 작성
- 재시도 시 Redis 부하를 막기 위한 Pub/Sub 기반 대기 로직 구현
- 비즈니스 연산 지연 시 데드락을 막으면서도 안전하게 만료 시간을 늘려줄 타이머(Watch Dog) 구현
반면, Redisson은 RLock 인터페이스 하나로 이 모든 고도화된 동시성 제어 인프라를 한 번에 제공한다.
그렇기 때문에 상품 재고 차감, 선착순 쿠폰 발급, 중복 결제 방지처럼 한 끗 차이로 데이터 정합성이 깨질 수 있는 크리티컬한 비즈니스 로직에서는 실무에서 Redisson을 활용한 분산 락 제어가 사실상의 표준(De facto standard)으로 자리 잡게 된 것이다.
2. Spring Data Redis vs Redisson 최종 비교
지금까지 Spring Data Redis를 이용한 직접 구현 방식과 Redisson을 이용한 분산 락 구현 방식을 모두 살펴보았다. 결론부터 이야기하면 Spring Data Redis로도 분산 락 구현 자체는 가능하다. 하지만 정합성이 중요하고 트래픽이 몰리는 실무 서비스라면 Redisson을 도입하는 것이 훨씬 안전하고 생산적이다. 왜 그런지 핵심 항목별로 깊이 있게 비교해 보자.
한눈에 보는 분산 락 구현 비교
| 비교 항목 | Spring Data Redis (직접 구현) | Redisson (라이브러리 활용) |
| 코드 복잡도 | 높음 (UUID 생성, 락 실패 처리, Lua Script 작성 등 바닥부터 직접 구현) | 낮음 (tryLock() 호출 및 unlock()으로 간결하게 처리) |
| 재시도 방식 | Spin Lock (루프를 돌며 무차별 획득 시도로 Redis 서버 CPU 과부하 유발 가능) | Pub/Sub 기반 (락이 해제될 때만 신호를 받아 시도하므로 네트워크 부하 최소화) |
| 락 만료(TTL) 처리 | 개발자가 고정 임의 지정 (작업이 설정한 TTL보다 길어지면 동시성 제어 붕괴) | Watch Dog 지원 (스레드가 살아있는 한 TTL을 주기적으로 자동 연장) |
| 안정성 & 예외 대응 | 낮음 (소유권 검증 미비 시 타인의 락을 해제하는 등 휴먼 에러 위험 존재) | 높음 (식별 정보가 내장되어 타인의 락 해제 불가, 수많은 서비스에서 검증됨) |
| 미세 성능 (처리 속도) | 상대적으로 아주 미세하게 빠름 (추가 인프라 레이어가 없어 가벼움) | 미세하게 무거움 (안전장치 계층이 존재하나 실무상 체감하기 어려운 수준) |
항목별 심층 분석
1. 코드 복잡도와 생산성
- Spring Data Redis: 락 하나를 걸고 풀기 위해 UUID로 소유권을 식별하고, setIfAbsent 결과를 검증하고, finally 블록에서 검증과 삭제를 원자적으로 처리하기 위한 Lua Script까지 작성해야 한다. 비즈니스 로직보다 락을 제어하는 부가 코드가 더 길어진다.
- Redisson: RLock 객체를 가져와 tryLock()을 호출하는 것이 전부다. 자바 표준 락을 쓰듯 직관적이어서 비즈니스 로직의 가독성이 명확히 살아난다.
2. 장시간 작업 대응 (TTL의 한계)
- Spring Data Redis: 외부 API 지연이나 DB 부하로 인해 작업 시간이 조금이라도 삐끗해서 내가 설정한 TTL(예: 3초)을 넘기는 순간 락이 강제로 풀린다. 동시성을 잡으려고 만든 락이 무력화되는 순간이다.
- Redisson: Watch Dog이 백그라운드에서 스레드의 생존 여부를 감시하며 TTL을 자동으로 연장한다. 네트워크가 일시적으로 느려지거나 대량의 배치가 돌더라도 데이터 정합성이 깨질 위험이 없다.
3. "직접 구현하는 게 더 빠르지 않나요?" (성능에 대한 오해)
이론적으로는 Spring Data Redis 직접 구현이 외부 라이브러리 레이어를 거치지 않기 때문에 아주 미세하게 더 가볍고 빠를 수 있다. 하지만 실무 웹 애플리케이션 환경에서 이 차이는 대세에 전혀 영향을 주지 않는 미미한 수준이다. 아키텍처를 설계할 때는 아주 미세한 초당 처리량의 이점보다, 데이터가 깨지지 않는 안정성과 동료 개발자가 읽기 좋은 유지보수성이 훨씬 더 중요하다.
2.1 언제 무엇을 선택해야 할까?
프로젝트 상황에 따라 아래의 기준을 참고하여 선택하면 가장 깔끔하다.
Spring Data Redis만으로 충분한 경우
- JWT Access / Refresh Token 저장 및 검증
- 이메일 인증번호 유효시간 관리
- 단순 조회 성능 개선을 위한 로컬/글로벌 캐싱
- 토이 프로젝트나 학습 목적의 분산 락 실습
Redisson을 사용하는 것이 좋은 경우
- 상품 재고 차감 및 선착순 이벤트
- 중복 결제 및 중복 주문 방지
- 수강신턴, 항공권/티켓 예약 시스템
- 멀티 서버 환경에서의 스케줄러/배치 중복 실행 방지
- 한 끗 차이로 데이터 정합성이 깨지면 금전적/서비스적 타격이 큰 모든 곳
2.2 결론: 현재 프로젝트에서 내린 최종 아키텍처
처음에는 단순히 고속으로 읽고 쓰며 만료 시간(TTL) 관리가 필요한 JWT Refresh Token을 안전하게 저장하기 위해 프로젝트에 Redis를 도입했다. 하지만 서비스가 확장되고 상품 재고 정합성을 고민하게 되면서 자연스럽게 분산 락이라는 고도화된 동시성 주제를 마주하게 되었다. 조사를 시작하며 가졌던 가장 근본적인 의문, "Spring Data Redis로도 분산 락을 만들 수 있는데 왜 굳이 Redisson을 따로 쓸까?"에 대한 답은 명확했다. Spring Data Redis는 분산 락을 '구현'할 수 있지만, 구현 이후 운영 환경에서 발생하는 수많은 사이드 이펙트와 예외 상황까지 개발자가 온전히 책임져야 한다. 반면 Redisson은 분산 락을 '안전하게 운영'하기 위해 필요한 모든 안전장치(Watch Dog, Pub/Sub, 소유권 검증)를 이미 완성도 높게 제공한다. 그 결과, 현재 우리 프로젝트는 다음과 같이 가장 이상적이고 안전한 역할 분리를 선택하여 운영하고 있다.
- Spring Data Redis (Lettuce 엔진) → 일반적인 Key-Value 데이터 접근 및 JWT 토큰 관리 담당
- Redisson (org.redisson:redisson 코어) → 버전 호환성 리스크 없이, 필요한 비즈니스에만 독립적인 분산 락 및 동시성 제어 담당
결국 중요한 것은 어떤 유명한 라이브러리를 맹목적으로 추종하느냐가 아니다. 내가 지금 해결하려는 문제가 단순한 '데이터 저장/조회 문제'인가, 아니면 여러 프로세스가 얽히는 '동시성 제어 문제'인가를 명확히 구분하는 것이다. 이번 프로젝트에서 재고 관리의 정답은 후자였고, 그렇기에 Redisson은 대체 불가능한 최고의 선택이었다.
3. 구현 중 문제 정의: 왜 재고 동시성 제어가 필요한가?
지금까지 Redis 설명은 모두 지금부터 시작하는 내용을 위한 최소한의 사전 지식이었다. 프로젝트에서 겪은 동시성 문제를 해결하기 위한 흐름이 진짜 내용이다. 결론부터 말하자면, 지금 Redisson 만으로도 재고 차감을 완벽하게 정합성, 성능, 코드 품질 등 모든 것을 잡은 것은 아니다. 그럼에도 불구하고, Redisson 분산 락을 선택한 이유도 함께 알아보는 포인트로 삼으면 좋다.
3.1 재고 차감은 생각보다 어려운 문제다
전자상거래(E-Commerce) 서비스에서 '주문'은 가장 핵심적이고 흔하게 발생하는 기능이다. 사용자가 상품을 조회하고, 주문을 생성한 뒤 결제를 진행하는 과정은 겉보기에는 단순해 보이지만, 대규모 트래픽이 발생하는 실제 운영 환경에서는 반드시 해결해야 하는 치명적인 문제가 존재한다. 바로 재고 정합성(Stock Consistency)이다. 예를 들어 특정 한정판 상품의 재고가 10개 남아 있다고 가정해 보자.
- [상품 A 재고 상태]: `totalQuantity = 10`
이 상황에서 100명의 사용자가 동시에 주문 버튼을 누르면 어떤 일이 발생할까?
멀티스레드 환경에서 모든 요청이 동일한 시점에 DB의 재고 데이터를 조회한다면, 다음과 같은 시나리오가 전개된다.
- 사용자 A ──> 재고 조회 (10개 확인) ──> 차감 요청 (10 - 1 = 9)
- 사용자 B ──> 재고 조회 (10개 확인) ──> 차감 요청 (10 - 1 = 9)
- 사용자 C ──> 재고 조회 (10개 확인) ──> 차감 요청 (10 - 1 = 9)
각 스레드가 서로의 수정 사항을 알지 못한 채 데이터베이스에 접근하여 동시에 재고를 차감하면, 실제 보유한 재고보다 훨씬 많은 수의 주문이 성공하게 된다. 이를 초과 판매(Overselling) 문제라고 부른다.
- 실제 재고: 10개
- 주문 성공: 100건
- 최종 재고 결과: $-90$개
이는 서비스의 신뢰도를 실추시키고 강제 취소에 따른 추가 비용을 발생시키므로,
실제 쇼핑몰 서비스에서는 절대 발생해서는 안 되는 결함이다.
3.2 현재 프로젝트의 주문 흐름
초과 판매를 막기 위해 시스템 레이어에서 동시성을 제어하기에 앞서, 비즈니스 요구사항에 맞는 올바른 주문 흐름을 정의해야 한다. 현재 프로젝트의 주문 프로세스는 다음과 같이 구조화되어 있다.
- `[상품 조회] ──> [주문 생성] ──> [재고 예약] ──> [결제 진행] ──> [결제 성공] ──> [재고 확정]`
여기서 주목해야 할 점은 주문 생성 시점에 즉시 판매 수량을 증가시키거나 전체 재고를 깎지 않는다는 점이다. 주문 생성과 결제 성공은 서로 다른 시점에 발생하는 별개의 트랜잭션이기 때문이다. 만약 사용자가 주문만 생성해 두고 결제 페이지에서 이탈하거나 결제에 실패한다면 어떻게 될까?
- `[주문 생성 성공] ──> [결제 페이지 이탈 / 결제 실패]`
이미 재고를 완전히 차감해 버렸다면, 실제 판매는 이루어지지 않았음에도 다른 사용자가 해당 상품을 구매하지 못하는 재고 잠김 현상이 발생한다. 이로 인해 유실되는 매출 기회비용을 방지하고자, 본 프로젝트에서는 재고 상태를 단순히 하나의 수량으로 관리하지 않고 '예약 상태'와 '판매 상태'로 세분화하여 관리하기로 결정했다.
1.3 재고를 예약 상태로 관리한 이유
비즈니스 요구사항을 충족하기 위해 ProductStock 도메인의 재고 상태를 다음 세 가지 필드로 분리하여 설계했다.
- `totalQuantity`: 확보된 전체 재고 수량 (예: 100개)
- `reservedQuantity`: 주문은 생성되었으나 아직 결제가 완료되지 않은 '선점' 수량 (예: 20개)
- `soldQuantity`: 결제가 최종 완료되어 실제 판매된 수량 (예: 30개)
이 상태 구조에서 실질적으로 고객이 구매할 수 있는 현재 판매 가능 재고(availableQuantity)는 다음과 같은 공식을 통해 정적 계산(Calculated)된다.

예시 데이터 적용
- `totalQuantity` = 100
- `reservedQuantity` = 20
- `soldQuantity` = 30
- `결과: availableQuantity` = 50
1.4 ProductStock 도메인 모델
상기 명시한 캡슐화와 불변식을 보장하기 위해 별도의 ProductStock 애그리거트(Aggregate)를 설계했다.
재고의 가용 상태를 판단하고 수량을 변경하는 모든 핵심 비즈니스 로직은 도메인 모델 내부로 응집된다.
public class ProductStock {
private int totalQuantity;
private int reservedQuantity;
private int soldQuantity;
// 가용 재고 계산
public int availableQuantity() {
return totalQuantity - reservedQuantity - soldQuantity;
}
// 재고 예약 (주문 생성 시)
public void reserve(int quantity) {
if (availableQuantity() < quantity) {
throw new InsufficientStockException("가용 재고가 부족합니다.");
}
this.reservedQuantity += quantity;
}
// 예약 해제 (주문 취소 / 결제 실패 시)
public void release(int quantity) {
if (this.reservedQuantity < quantity) {
throw new InvalidStockArgumentException("해제할 예약 재고가 부족합니다.");
}
this.reservedQuantity -= quantity;
}
// 판매 확정 (결제 완료 시)
public void confirm(int quantity) {
if (this.reservedQuantity < quantity) {
throw new InvalidStockArgumentException("확정할 예약 재고가 부족합니다.");
}
this.reservedQuantity -= quantity;
this.soldQuantity += quantity;
}
}
이 구조의 핵심은 서비스 계층(Service Layer)이 직접 재고 수량을 조작하지 못하도록 차단하는 데 있다. 모든 상태 변경은 객체 내부 메서드(`reserve, release, confirm`)를 통해서만 수행되며, 가용 재고 검증과 같은 재고 관련 불변식(Invariants)은 오직 ProductStock이 스스로 책임진다. 객체지향적인 관점에서 안전한 도메인 모델이 완성된 것이다.
1.5 하지만, 이것만으로는 부족했다
풍부한 도메인 모델(Rich Domain Model)을 구축함으로써 비즈니스 규칙을 안전하게 격리하고 검증할 수 있게 되었다. 단일 스레드 환경이라면 이 모델만으로도 완벽하게 동작할 것이다. 하지만 데이터베이스와 어플리케이션이 멀티스레드로 동작하는 환경에서는 여전히 해결되지 않는 근본적인 문제가 남아 있었다. 바로 '동시성(Concurrency)'이다.
예를 들어 ProductStock이 초기 상태(`totalQuantity = 10`, `reservedQuantity = 0`, `soldQuantity = 0`)일 때, 동시에 100개의 주문 요청이 밀려온다고 가정해 보자. 어플리케이션 레이어의 도메인 규칙이 아무리 완벽하게 작성되어 있어도, 각 스레드가 '동시에 상태를 읽고(Race Condition), 동시에 수정하는 문제' 자체를 데이터베이스 레이어나 분산 환경에서 막아주지는 못한다. 100개의 스레드가 동시에 `availableQuantity()`를 호출하면 모두 10이라는 결과를 보게 되고, 너나 할 것 없이 `stock.reserve(1)`을 통과하여 최종적으로 예약 수량이 100으로 튀어버리는 대참사가 발생한다.
결국 도메인 모델의 규칙이 무너지지 않도록 재고 정합성을 물리적으로 보장할 수 있는 동시성 제어 전략이 필수적이라는 결론에 도달했다. 이에 따라 가장 먼저 검토하고 적용한 첫 번째 고전적 제어 기법은 바로 JPA의 낙관적 락(Optimistic Lock)이었다.
2장. ProductStock 도메인 설계
2.1 재고는 단순 숫자가 아니다
가장 직관적인 재고 관리 방식은 DB 테이블에 단일 컬럼을 두고 숫자를 더하거나 빼는 구조다.
- [초기 상태] `product_id: 1`, `stock: 100`
- 주문 발생: `stock -= quantity`
- 결제 취소: `stock += quantity`
단순하지만, 이 방식은 실제 이커머스의 주문 프로세스를 반영하지 못한다.
고객이 주문 버튼을 누른 순간부터 실제 결제가 완료되기까지는 대기 시간이 존재하기 때문이다.
- 주문 프로세스 흐름: `주문 생성 ──> 결제창 진입 ──> 결제 수단 선택 ──> 결제 승인 요청 ──> 결제 완료`
이 과정은 수 초에서 수 분까지 소요되며, 사용자가 중간에 브라우저를 닫아버리는 '결제 이탈' 시나리오도 빈번하게 발생한다.
이 대기 시간 동안 재고를 어떻게 처리할 것인지가 도메인 설계의 핵심 과제다.
2.2 재고를 즉시 차감하는 경우 (주문 생성 시점)
"주문 생성과 동시에 재고를 즉시 차감"하면 어떤 문제가 발생할까?
- `[재고: 10개] ──> 주문 생성 ──> [재고: 9개] ──> 결제 미진행 (주문 방치/이탈)`
실제 판매는 일어나지 않았는데 재고만 줄어든 상태가 된다. 이러한 '미결제 방치 주문'이 수백 건 누적되면, 창고에 물건은 가득한데 웹사이트에서는 품절로 표시되어 물건을 팔지 못하는 재고 잠김(Inventory Lockup) 현상이 발생한다. 즉, 비즈니스 측면에서 심각한 매출 기회 손실로 이어진다.
2.3 결제 성공 시점에만 차감하는 경우
반대로 "주문 생성 시점에는 아무 작업도 하지 않고, 최종 결제가 완료되는 순간에만 재고를 차감"하면 어떻게 될까?
- [초기 재고: 10개]
- 100명의 사용자 동시에 주문 생성 성공 (주문서 100건 발행)
- 100명의 사용자 동시에 결제 시도
- 선착순 10명 결제 승인 성공 / 나머지 90명 결제 승인 실패
기술적으로는 오버셀링을 막은 것처럼 보이지만, "사용자 경험(UX) 측면에서는 최악의 상황"이 된다. 사용자는 이미 주문서를 성공적으로 생성하고 카드 번호까지 입력했는데, 결제 완료 버튼을 누른 순간 "재고가 부족합니다"라는 뜬금없는 에러를 마주하게 된다.
2.4 예약(Reserve) 개념 도입
사용자 경험을 해치지 않으면서 재고 잠김 현상도 방지하기 위해, 내 프로젝트는 '예약(Reserve) 후 확정(Confirm)' 구조를 선택했다. 주문이 생성되는 시점에는 상품을 완전히 판매된 것으로 처리하지 않고, 잠시 '선점'해 두는 예약 상태로 전환하는 방식이다.
- [재고: 10개 상품에 1개 주문 생성]
- `reservedQuantity`(예약 재고) : 0 ──> 1 증가
- `soldQuantity`(판매 재고) : 0 유지
- [결제 최종 성공 시]
- `reservedQuantity` (예약 재고) : 1 ──> 0 감소
- `soldQuantity` (판매 재고) : 0 ──> 1 증가
이 방식을 사용하면 주문 생성 시점에 안전하게 자리를 선점해 주되,
결제에 실패하거나 이탈하면 예약된 수량만 다시 복구해주면 되므로 두 가지 문제를 모두 해결할 수 있다.
2.5 ProductStock Aggregate 설계
이러한 요구사항을 반영하여 단일 수량이 아닌,
성격이 다른 세 가지 재고 필드를 가진 ProductStock 애그리거트(Aggregate)를 설계했다.
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class ProductStock {
@Id
private Long productId;
private int totalQuantity; // 전체 재고 (창고에 실제 존재하는 수량)
private int reservedQuantity; // 예약 재고 (주문은 되었으나 결제 대기 중인 수량)
private int soldQuantity; // 판매 재고 (결제가 완료되어 출고될 수량)
}
2.6 판매 가능한 재고 계산
고객에게 노출되어야 하는 실질적인 판매 가능 재고(availableQuantity)는 고정된 컬럼이 아니라,
도메인 내부에서 실시간으로 계산(Calculated)된다.
public int availableQuantity() {
return totalQuantity - reservedQuantity - soldQuantity;
}
비즈니스 데이터 대입 예시
- 전체 재고(totalQuantity): 100개
- 예약 재고(reservedQuantity): 20개
- 판매 재고(soldQuantity): 30개
- 판매 가능 재고(availableQuantity) = 100 - 20 - 30 = 50개
2.7 재고 불변식(Invariant)
재고 시스템의 무결성을 유지하기 위해 어떤 상황에서도 깨져서는 안 되는 불변식(Invariant)을 다음과 같이 정의했다.
- 규칙 1: `reservedQuantity >= 0` (예약 재고는 음수가 될 수 없다)
- 규칙 2: `soldQuantity >= 0` (판매 재고는 음수가 될 수 없다)
- 규칙 3: `availableQuantity >= 0` (판매 가능 재고는 절대 0 미만으로 떨어질 수 없다)
- 규칙 4: `reservedQuantity + soldQuantity <= totalQuantity` (예약과 판매의 합은 전체 재고를 초과할 수 없다)
이 불변식이 깨지는 순간 시스템에는 마이너스 재고, 초과 판매, 데이터 불일치 등의 치명적인 결함이 발생한다.
2.8 도메인 행위 메서드 구현
1) 재고 예약 (reserve)
주문 생성 시점에 가용 재고를 확인하고 예약 수량을 확보한다.
public void reserve(int quantity) {
validatePositiveQuantity(quantity);
if (!hasAvailableQuantity(quantity)) {
throw new ProductException(ProductErrorCode.INSUFFICIENT_STOCK);
}
this.reservedQuantity += quantity;
}
private boolean hasAvailableQuantity(int quantity) {
return availableQuantity() >= quantity;
}
2)재고 예약 취소 (release)
주문 취소나 결제 실패 시, 기존에 예약해 두었던 수량을 다시 가용 재고로 돌려놓는다.
기존 예약된 수량을 초과하여 복구할 수 없도록 검증 로직을 포함한다.
public void release(int quantity) {
validatePositiveQuantity(quantity);
if (this.reservedQuantity < quantity) {
throw new ProductException(ProductErrorCode.CANNOT_RELEASE_MORE_THAN_RESERVED_STOCK);
}
this.reservedQuantity -= quantity;
}
3) 재고 확정 (confirm)
결제 승인이 완료되면 예약 상태에 있던 재고를 실제 판매 상태로 전이시킨다.
public void confirm(int quantity) {
validatePositiveQuantity(quantity);
if (this.reservedQuantity < quantity) {
throw new ProductException(ProductErrorCode.CANNOT_CONFIRM_MORE_THAN_RESERVED_STOCK);
}
this.reservedQuantity -= quantity;
this.soldQuantity += quantity;
}
2.9 ProductStock이 모든 규칙을 책임지는 이유
이 설계에서 가장 중요한 점은 외부 서비스 계층(Service Layer)에서 `stock.setReservedQuantity(...)`와 같이 상태를 외부에서 직접 조작하는 세터(Setter) 메서드가 완전히 배제되었다는 것이다. 모든 재고의 상태 변경은 오직 `reserve()`, `release()`, `confirm()`이라는 명확한 의미를 가진 비즈니스 메서드를 통해서만 이루어진다.
즉, 재고 관련 비즈니스 규칙과 불변식 검증은 ProductStock 애그리거트 내부에 철저히 캡슐화되어 있다. 이 덕분에 서비스 계층은 비즈니스 흐름 상에서 "무엇을 할 것인가(What)"만 결정하고, 데이터의 정합성을 유지하며 "어떻게 재고를 변경할 것인가(How)"는 오직 도메인 모델 객체 스스로가 책임지게 된다.
2.10 하지만 아직 해결되지 않은 문제가 있었다
객체지향적인 ProductStock 도메인 설계를 통해 복잡한 재고 비즈니스 모델링과 데이터 검증 문제는 훌륭하게 해결했다. 단일 스레드 기반의 테스트는 완벽하게 통과한다. 하지만 데이터베이스와 어플리케이션이 멀티스레드로 동작하는 실제 운영 환경에서는 여전히 치명적인 문제가 남아 있었다. 바로 '동시성(Concurrency)'이다.
재고가 10개 남은 상품에 100개의 주문 요청이 동시에 들어오면, 여러 스레드가 동시에 `availableQuantity()`를 조회하게 된다. 이때 모든 스레드가 아직 데이터베이스에 반영되지 않은 변경 전 상태(재고 10개)를 읽어오기 때문에, 모두가 `hasAvailableQuantity()` 검증을 통과하고 `stock.reserve(1)`을 실행하게 된다. 결국 도메인 내부 규칙을 아무리 단단하게 짜놓았더라도, "동시에 읽고 동시에 수정하는 멀티스레드 환경의 경쟁 상태(Race Condition)"는 도메인 모델 단독으로 막을 수 없다. 이에 따라 우리는 도메인 모델의 불변식을 물리적으로 보호하고 재고 정합성을 보장하기 위해, 다음 단계로 JPA의 낙관적 락(Optimistic Lock)을 적용하여 동시성 제어에 나서게 되었다.
3. 1차 접근: JPA Optimistic Lock (낙관적 락)
동시성 문제를 해결하기 위한 첫 번째 선택
ProductStock 애그리거트 설계를 통해 도메인 규칙을 단단히 굳혔지만, 멀티스레드 환경에서는 여전히 무력했다.
재고가 10개 남은 상황에서 100개의 주문 요청이 동시에 발생하면 모든 스레드가 동일한 엔티티를 조회하기 때문이다.
// 100개의 스레드가 거의 동시에 같은 행(Row)을 조회
ProductStock stock = productStockRepository.findByProductId(productId)
.orElseThrow();
// 모든 스레드가 가용 재고를 10개로 인식하고 검증을 통과함
stock.reserve(1);
각 트랜잭션이 동일한 데이터의 스냅샷을 보고 상태를 변경한 뒤 DB에 커밋을 시도하면, 두 개 이상의 트랜잭션이 한 데이터를 동시에 수정할 때 발생하는 두 번의 갱신 분실 문제(Lost Update Problem)를 직면하게 된다.
3.1 Lost Update(두 번의 갱신 분실)란 무엇인가?
예를 들어 현재 `totalQuantity = 10`, `reservedQuantity = 0`인 상품이 있다.
여기에 두 개의 주문 트랜잭션이 동시에 진입하는 시나리오를 보자.
- 트랜잭션 A: reservedQuantity = 0 조회 ──> reserve(1) 호출 (메모리상 reservedQuantity = 1)
- 트랜잭션 B: reservedQuantity = 0 조회 ──> reserve(1) 호출 (메모리상 reservedQuantity = 1)
두 트랜잭션 모두 가용 재고가 충분하다고 판단하여 정상적으로 비즈니스 로직을 통과한다. 이후 각각의 변경 사항을 DB에 저장한다.
- 트랜잭션 A 커밋 ──> DB 반영 (reservedQuantity = 1)
- 트랜잭션 B 커밋 ──> DB 반영 (reservedQuantity = 1)
두 명의 사용자가 재고를 1개씩 예약했으므로 기대하는 정상 결과는 `reservedQuantity = 2`다. 하지만 실제 결과는 `1`이 된다. 나중에 커밋된 트랜잭션 B가 먼저 커밋된 트랜잭션 A의 변경 내용을 아무런 경고 없이 덮어써 버렸기 때문이다. 이를 Lost Update 문제라고 하며, 이 현상이 누적되는 순간 재고 정합성은 완전히 무너진다.
3.2 Optimistic Lock(낙관적 락)을 선택한 이유
JPA(Hibernate)는 어플리케이션 레벨에서 이 문제를 방지할 수 있도록 낙관적 락(Optimistic Lock)을 제공한다. 데이터베이스의 물리적인 락(Exclusive Lock 등)을 사용하지 않고, 애플리케이션이 자체적으로 데이터의 버전을 관리하여 정합성을 지키는 방식이다.
적용은 매우 직관적이고 단순하다. 엔티티에 `@Version` 어노테이션이 붙은 필드 하나만 추가하면 된다.
@Entity
public class ProductStock {
@Id
private Long productId;
private int totalQuantity;
private int reservedQuantity;
private int soldQuantity;
@Version
private Long version; // 낙관적 락을 위한 버전 관리 필드
}
이 한 줄만 추가하면, 엔티티가 수정될 때마다 Hibernate가 내부적으로 버전 메커니즘을 가동한다.
1) version 필드를 직접 조작하지 않는데 왜 동작할까?
처음 낙관적 락 코드를 접하면 의문이 생기기 마련이다. 비즈니스 로직 어디에도 `stock.getVersion()`으로 값을 검사하거나, `version++`를 수행하는 코드가 없기 때문이다. 이것이 가능한 이유는 JPA 구현체인 Hibernate가 엔티티의 라이프사이클을 추적하며 필요한 처리를 가로채기(Intercept) 때문이다. 개발자가 비즈니스 도메인에만 집중할 수 있도록 persistence layer 뒤에서 SQL을 동적으로 제어한다.
2) Hibernate 내부 동작 메커니즘
동일한 스냅샷을 가진 트랜잭션 A와 B가 경합하는 상황을 통해 Hibernate의 실제 내부 동작을 뜯어보자.
- [초기 DB 상태] `id = 1`, `reserved_quantity = 0`, `version = 0`
- 동시 조회: 트랜잭션 A와 B가 거의 동시에 조회를 수행한다. 두 트랜잭션 모두 메모리에 `version = 0`인 엔티티 스냅샷을 확보한다.
- 트랜잭션 A 커밋: A가 먼저 수정을 시도하면 Hibernate는 다음과 같은 SQL을 생성하여 전송한다. 조건절의 `version = 0`이 현재 DB 상태와 일치하므로 업데이트가 성공하고, DB의 version은 1로 상승한다.
- A의 SQL 쿼리문
-
UPDATE v1_product_stocks SET reserved_quantity = 1, version = 1 WHERE id = 1 AND version = 0; - 트랜잭션 B 커밋: 조금 늦은 B가 커밋을 시도한다. B 역시 자신이 조회했던 시점의 버전(`0`)을 기준으로 SQL을 보낸다.하지만 현재 DB의 version은 이미 A에 의해 `1`로 변경된 상태다. 따라서 `WHERE version = 0` 조건에 맞는 행을 찾을 수 없다.
-
B의 SQL 쿼리문
UPDATE v1_product_stocks SET reserved_quantity = 1, version = 1 WHERE id = 1 AND version = 0; - 결과 감지: 쿼리 실행 결과로 반환된 Affected Rows(영향을 받은 행의 수)가 0이 된다. Hibernate는 이 신호를 받아 "내가 읽은 이후에 누군가 데이터를 먼저 수정했구나"라고 판단하고 트랜잭션을 롤백하며 예외를 던진다.
- `ObjectOptimisticLockingFailureException` (Spring 예외 래핑)
- `StaleObjectStateException` 또는 `StaleStateException` (Hibernate 원천 예외)
3.3 Optimistic Lock의 핵심: 충돌을 막지 않는다
많은 개발자가 범하는 치명적인 오해가 있다. "Optimistic Lock을 걸었으니 동시 요청이 들어와도 안전하게 차례대로 처리되겠지?"라고 기대하는 것이다. 그러나 단어 뜻 그대로 낙관적 락은 "대부분의 상황에서 충돌이 나지 않을 것이다"라고 낙관적으로 가정하고 접근하는 기술이다.
- 낙관적 락의 본질: 충돌 예방(Prevention)이 아니라 충돌 감지(Detection)다.
따라서 데이터베이스에 무거운 락을 걸어 타임아웃을 유발하거나 대기 스레드를 만들지 않는 대신,
"먼저 커밋한 요청만 성공시키고, 늦은 요청은 실패(예외 발생) 처리할 테니 후처리는 알아서 해라"에 가깝다.
1) 프로젝트에 적용했던 이유와 기대 결과
당시 도입 목표는 1장에서 정의했던 '재고 정합성 보장'과 '초과 판매(Overselling) 방지'였다. 낙관적 락을 적용하면 대규모 동시성 요청 속에서도 데이터가 덮어씌워지는 대참사는 확실히 막을 수 있어 보였다. 우리가 기대했던 시나리오는 다음과 같았다.
- 기대 상황: 재고 10개인 상품에 100명이 동시에 주문을 넣는다.
- 예상 결과: 가장 빠르게 도달한 정확히 10개의 요청만 성공하여 재고를 소진하고,
나머지 90개의 요청은 낙관적 락 예외가 발생하여 안전하게 주문 실패 처리된다. - 결론: 데이터 정합성 만족, 초과 판매 발생 안 함.
2) 예상하지 못한 심각한 부작용의 발견
낙관적 락을 적용하고 100개의 동시 요청 테스트를 수행한 결과, 재고 정합성 자체는 완벽하게 지켜졌다. 최종 가용 재고는 정확히 0이 되었고, 단 한 건의 초과 판매도 발생하지 않았다. 하지만 실패한 요청들의 에러 지표를 뜯어보았을 때, 비즈니스 관점에서 도저히 묵과할 수 없는 심각한 부작용이 발견되었다. 우리가 처음에 낙관적 락에 기대했던 시나리오는 다음과 같았다.
- 이상적인 시나리오: 100개의 요청 중 선착순 10개가 순차적으로 재고를 예약(successCount = 10)하고,
나머지 90개의 요청은 깔끔하게 "재고 부족" 비즈니스 예외(ProductException)를 맞이하며 실패하는 것.
그러나 실제 테스트 결과 분석을 통해 마주한 지표는 충격적이었다. 낙관적 락 동시성 테스트 에러 지표 분석

===== Optimistic Lock 동시성 테스트 결과 =====
initialStock = 10 | requestCount = 100
successCount = 10 | failCount = 90
exceptionCounts = {
ObjectOptimisticLockingFailureException = 84, // DB 버전 충돌
StaleObjectStateException = 84, // DB 버전 충돌 (원인 예외)
ProductException = 6 // 순수 재고 부족 예외
}
실패한 90건의 요청 중, 우리가 원했던 "재고가 없어서 실패"한 건수는 단 6건에 불과했다. 나머지 84건의 요청은 재고가 아직 남아있음에도 불구하고 오직 DB 버전 충돌(ObjectOptimisticLockingFailureException) 때문에 튕겨 나간 것이다. 예를 들어, 첫 번째 요청이 커밋되어 버전이 0에서 1로 오르는 순간, 동시에 버전 0을 읽고 대기하던 수십 개의 스레드가 비즈니스 검증(재고가 충분한지 확인하는 로직)은 통과해 놓고 정작 커밋 시점에 통통 튕겨 나가며 에러를 뿜었다. 결과적으로 최종 성공 횟수(successCount)는 어떻게든 10건을 채웠지만, 대다수의 사용자는 "재고가 남아있는데도 서버 시스템 내부 충돌 에러로 인해 주문에 실패하는" 최악의 사용자 경험을 겪게 된다는 뜻이다.
3) 분산 락(Distributed Lock) 결과와의 미리보기 대조
이 문제가 얼마나 심각한지는 추후 도입하게 될 Redis 분산 락의 테스트 결과와 비교해 보면 더 명확해진다.
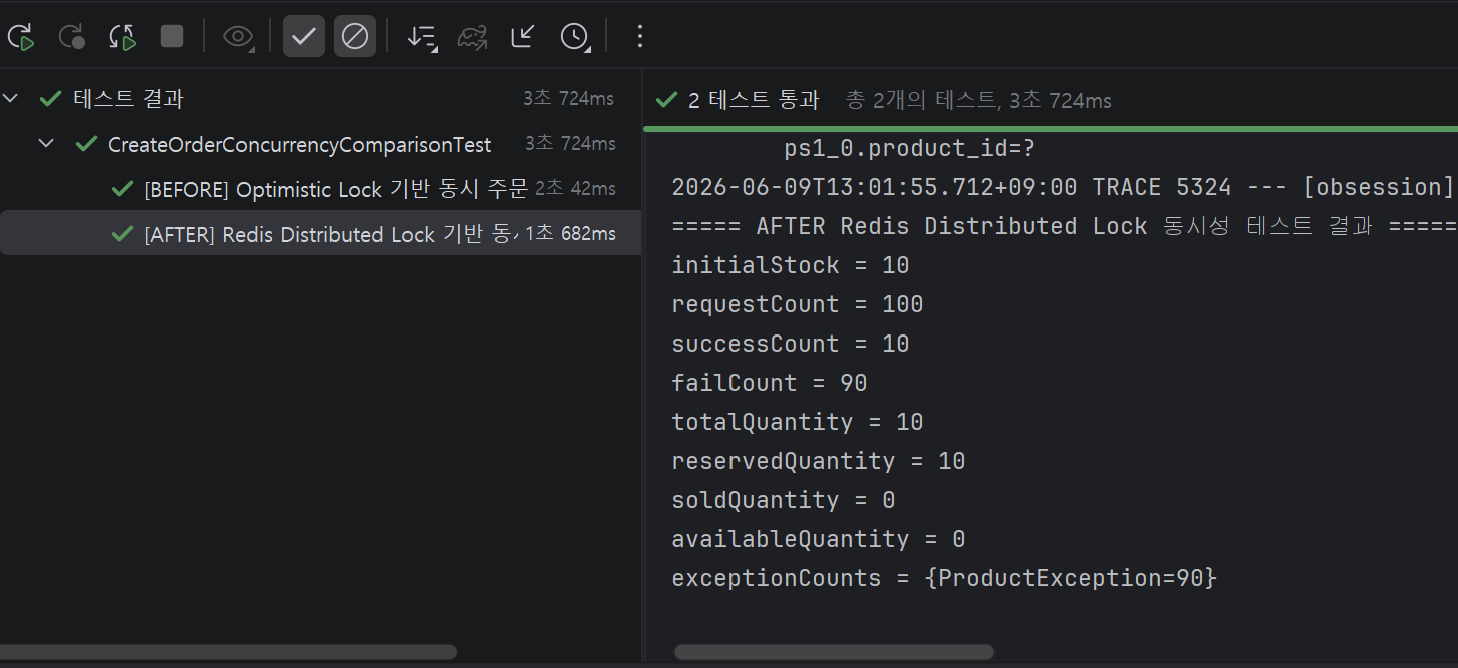
===== AFTER Redis Distributed Lock 동시성 테스트 결과 =====
successCount = 10 | failCount = 90
exceptionCounts = { ProductException = 90 } // 100% 비즈니스 예외로만 실패
순차성을 보장하는 분산 락 환경에서는 시스템 충돌 에러가 0건이며, 실패한 90명 모두가 정상적으로 "재고가 부족합니다"라는 안내를 받는다. 반면 낙관적 락은 동시 요청이 한 곳으로 몰리는 '핫스팟' 환경에서 정상적인 비즈니스 흐름을 유실시키고 시스템 예외를 남발하는 한계를 극명하게 드러냈다. 시스템이 재고 부족을 우아하게 처리하지 못하고, 기술적 한계(버전 충돌)를 사용자에게 전가하고 있었던 것이다. 이 현상을 더 정밀하게 분석하고 증명하기 위해, 실제 작성했던 동시성 테스트 코드와 구체적인 실패 로그를 4장에서 자세히 살펴보자.
4. Optimistic Lock 기반 동시성 테스트
1) 정말 정합성이 보장될까?
Optimistic Lock을 적용한 뒤 가장 검증하고 싶었던 명제는 하나였다.
"실제 운영 환경에 준하는 고경합 트래픽이 몰려도 정말 초과 판매가 발생하지 않을까?"
이론적으로는 버전 메커니즘 덕분에 문제가 없어 보였다. 하지만 동시성 이슈는 실제 코드로 격리된 환경에서 부하를 주어 검증하기 전까지는 결코 확신할 수 없다. 특히 상품 재고 영역은 단 한 번의 정합성 버그가 곧바로 금전적 손실과 서비스 신뢰도 추락으로 이어지기 때문에 철저한 통합 테스트가 필수적이었다.
4.1 테스트 목표 및 기대 결과
이번 동시성 테스트의 목적은 간결하고 명확하다.
- 테스트 시나리오: 한정된 재고 10개가 존재할 때, 100개의 주문 요청이 동시에 몰리는 상황을 재현한다.
- 기대 결과: 최상위 선착순 주문 10건만 성공하고, 나머지 90건은 실패하여 최종 가용 재고가 정확히 0으로 맞아떨어지는지 확인한다.
따라서 락의 메커니즘이 경쟁 상태(Race Condition)를 제어하여 초과 판매(Overselling)를 완벽히 차단하는지 검증하는 것이 핵심이다.
1) 테스트 조건 설정
의도적으로 데이터베이스와 애플리케이션 서버가 한 지점에서 가장 극심하게 충돌하는 '핫스팟 래치' 상황을 만들기 위해 다음과 같이 환경을 구성했다.
- 초기 재고 수량: 10개
- 동시 주문 요청 수: 100개
- 스레드 풀(Thread Pool): 32 (멀티스레드 환경을 시뮬레이션하기 위한 고정 크기 스레드 풀)
- 주문 조건: 모든 요청은 동일한 상품 ID에 대해 각각 정확히 1개씩 주문을 시도한다.
2) CountDownLatch를 사용한 '진짜 동시성' 제어
동시성 테스트를 작성할 때 가장 흔히 하는 실수는 for문 내부에서 `executor.submit()`을 단순히 호출하고 끝내는 것이다. 이 경우 스레드가 순차적으로 생성되고 실행 주기가 미세하게 어긋나면서, DB 입장에서는 동시 요청이 아니라 '순차적인 연쇄 요청'으로 받아들이게 된다. 즉, 경쟁 상태가 제대로 재현되지 않는다. 이 문제를 해결하고 100개의 스레드를 정확히 동일한 시점에 출발시키기 위해 CountDownLatch를 활용한 3단계 동기화 기법을 적용했다.
// 출발 신호를 보낼 단 하나의 래치
CountDownLatch startLatch = new CountDownLatch(1);
// 100개의 스레드가 모두 종료되었는지 대기하는 래치
CountDownLatch doneLatch = new CountDownLatch(requestCount);각 스레드는 생성이 완료되면 100개의 스레드가 모두 로딩될 때까지 기다린다. 모든 스레드가 준비 정렬을 마치면 `startLatch.countDown()`을 단 한 번 호출하여 100개의 스레드가 문자 그대로 동시에 DB를 향해 질주하도록 제어했다.
4.2 지표 수집 데이터 구조 (성공/실패 & 예외 분석)
멀티스레드 환경에서 안전하게 성공 및 실패 건수를 카운팅하기 위해 원자성을 보장하는 AtomicInteger를 사용했다. 또한, 단순히 실패 횟수만 세는 것은 원인 분석에 도움이 되지 않으므로 어떤 예외 때문에 실패했는지 유형별로 집계할 수 있도록 스레드 안전한 `ConcurrentHashMap`을 구축했다.
AtomicInteger successCount = new AtomicInteger();
AtomicInteger failCount = new AtomicInteger();
// 발생한 예외의 클래스명을 Key로, 발생 횟수를 Value로 저장
ConcurrentHashMap<String, AtomicInteger> exceptionCounts = new ConcurrentHashMap<>();
스레드 내부의 catch 블록에서 예외가 발생할 때마다 아래와 같이 수집하여,
실패 원인이 도메인 검증에 의한 '재고 부족'인지, 기술적 한계에 의한 '락 충돌'인지 명확히 분리해 냈다.
exceptionCounts.computeIfAbsent(e.getClass().getSimpleName(), k -> new AtomicInteger()).incrementAndGet();
4.3 동시성 테스트 핵심 코드
테스트 대상이 되는 서비스 레이어 호출부의 대략적인 구조는 다음과 같다.
100개의 스레드가 `startLatch.await()`를 통과하자마자 동일한 productId에 대해 일제히 주문 생성을 시도한다.
@Test
void 동시_주문_재고_차감_테스트_Optimistic_Lock() throws InterruptedException {
// given
int requestCount = 100;
int initialStock = 10;
// ... 초기 재고 10개 셋팅 및 래치 초기화
// when
for (int i = 0; i < requestCount; i++) {
executorService.submit(() -> {
try {
readyLatch.countDown();
startLatch.await(); // 동시에 출발하도록 대기
// 주문 생성 및 재고 예약 비즈니스 로직 실행
createOrderService.create(new CreateOrderCommand(memberId, List.of(new OrderLineCommand(productId, 1))));
successCount.incrementAndGet();
} catch (Exception e) {
failCount.incrementAndGet();
// 예외 맵에 기록
recordException(e);
} finally {
doneLatch.countDown();
}
});
}
doneLatch.await(); // 모든 스레드가 종료될 때까지 대기
// ... 결과 출력
}
1) 테스트 결과 리포트
실행 후 수집된 데이터 지표는 다음과 같았다.
===== BEFORE Optimistic Lock 동시성 테스트 결과 =====
initialStock = 10
requestCount = 100
successCount = 10
failCount = 90
[최종 DB 재고 상태]
totalQuantity = 10
reservedQuantity = 10
soldQuantity = 0
availableQuantity = 0
[발생한 예외 통계]
ObjectOptimisticLockingFailureException = 84
StaleObjectStateException = 84
StaleStateException = 84
ProductException = 6
2) 결과 해석: 절반의 성공, 그리고 숨겨진 한계
1. 재고 정합성 보호는 성공했다
최종 DB 상태를 보면 `reservedQuantity = 10`, `availableQuantity = 0`으로 정확히 맞아떨어졌다. 100개의 무자비한 동시 요청 속에서도 초과 예약이나 오버셀링은 단 한 건도 발생하지 않았다. JPA의 `@Version`을 활용한 Optimistic Lock이 데이터의 무결성을 깨뜨리지 않고 방어막 역할을 해냈음을 증명한다.
2. 비즈니스 관점에서의 처참한 실패
하지만 예외 통계 지표를 보는 순간 이 구조를 실무에 도입할 수 없다는 결론에 도달했다. 실패한 90건의 요청 중, 정상적으로 도메인 불변식을 통과하지 못해 발생한 순수 재고 부족 예외(ProductException)는 단 6건에 불과했다. 나머지 84건의 실패는 전부 기술적인 버전 충돌 에러(ObjectOptimisticLockingFailureException)였다. 이 지표가 현업에서 의미하는 바는 매우 치명적이다.
- 사용자 경험의 붕괴: 고객의 관점에서는 "상품이 매진되었습니다"라는 정제된 안내를 받는 것이 자연스럽다. 그러나 시스템은 "누군가 먼저 수정을 완료하여 데이터가 충돌했습니다"라는 내부 인프라성 에러를 가감 없이 던지고 있었다.
- 낮은 처리량과 유실되는 비즈니스: 첫 번째 성공 스레드가 버전을 0에서 1로 바꾸는 찰나, 아직 재고가 9개나 남아있음에도 불구하고 동일한 버전 0을 읽고 대기하던 나머지 80여 개의 스레드가 커밋 단계에서 전부 튕겨 나가 버렸다. 즉, 재고가 충분히 존재하는데도 시스템 충돌 때문에 강제로 주문에 실패하는 부작용이 발생한 것이다.
4.4 Optimistic Lock은 정답이 아니었다
테스트 데이터가 말해주는 결론은 명확했다. 낙관적 락은 정합성(Consistency)은 완벽히 보장하지만, 고경합 환경에서 정상적인 비즈니스 흐름을 우아하게 소화하는 선착순 제어에는 완전히 부적합하다. 우리가 직면한 과제는 '충돌이 난 후 사후에 감지하여 에러를 던지는 것'이 아니라, '동시 요청을 한 줄로 세워 충돌 자체를 원천적으로 예방하는 것'이었다. 낙관적인 가정 하에 동작하는 락의 한계를 깨닫고, 우리는 동시성 제어의 패러다임을 전환하여 외부 분산 자원을 활용한 Redis Distributed Lock(분산 락)을 아키텍처에 도입하기로 결정했다.
5장. Optimistic Lock의 한계와 대안 검토
1) 테스트 결과를 보고 생긴 근본적인 의문
4번의 동시성 테스트 결과를 다시 짚어보자. 데이터 정합성 측면에서 초과 판매는 없었다. 하지만 실패한 90건의 요청 중 84건이 도메인 로직(재고 부족)이 아닌, DB 버전 충돌(ObjectOptimisticLockingFailureException)로 인해 무더기로 튕겨 나갔다. 이 지표를 마주한 순간 기술적인 의문이 싹텄다.
"가용 재고가 아직 남아있는데도, 단지 동시에 커밋했다는 이유로 시스템 내부 에러를 내며 사용자 요청을 버리는 게 맞을까? 굳이 충돌이 발생한 뒤에 사후 처리를 해야 할까?"
5.1 낙관적 락은 결국 '충돌을 허용'한다
낙관적 락(Optimistic Lock)의 본질은 '충돌 예방'이 아니라 '충돌 사후 감지'다.
- [낙관적 락의 흐름]
100명 동시 진입 ──> 100명 모두 가용 재고 확인 (통과) ──> 커밋 시점에 버전 충돌 감지 ──> 1등 외 전부 실패 처리
단어 그대로 "대부분 충돌하지 않을 것"이라고 낙관하기 때문에 트랜잭션이 진행되는 동안에는 아무런 제어를 하지 않는다. 경합이 거의 없는 가벼운 도메인에서는 락 획득 비용이 없어 매우 효율적이다. 하지만 커머스의 재고 차감, 선착순 쿠폰 발급, 티켓팅 같은 도메인은 전혀 낙관적이지 않다. 하나의 자원을 두고 수많은 트레드가 동시에 달려드는 고경합(High Concurrency) 환경이다. 낙관적 락은 고경합 환경에서 대량의 롤백 비용을 유발하고 비즈니스 흐름을 유실시키는 구조적 한계를 지니고 있었다. 따라서 사후에 충돌을 감지하는 방식이 아닌, '애초에 충돌이 발생하지 않도록 진입 단계에서 막는 방식'이 필요하다는 결론에 도달했다.
5.2 두 번째 후보: 비관적 락 (Pessimistic Lock)
가장 먼저 떠오른 대안은 데이터베이스 수준에서 물리적인 락을 거는 비관적 락(Pessimistic Lock)이었다.
JPA에서는 `@Lock` 어노테이션 하나로 매우 쉽게 구현할 수 있기 때문이다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select p from ProductStock p where p.productId = :productId")
Optional<ProductStock> findByProductIdWithPessimisticLock(Long productId);
이 방식을 사용하면 데이터베이스 조회 시점에 `SELECT ... FOR UPDATE` 쿼리가 실행되며,
해당 Row의 독점 락(Exclusive Lock)을 획득한다.
- 트랜잭션 A ──> DB Row Lock 획득 ──> 재고 수정 및 커밋 (락 유지)
- 트랜잭션 B ──> DB Row Lock 획득 시도 ──> [Lock 대기] ──> A 커밋 후 락 획득 및 순차 실행
낙관적 락과 달리 '충돌 전 차단' 구조이기 때문에, 스레드들이 차례대로 줄을 서서 재고를 차감하게 된다. 버전 충돌로 튕겨 나가는 현상이 없으므로 우리가 원했던 선착순 비즈니스를 완벽히 구현할 수 있어 보였다. 그럼에도 비관적 락을 선택하지 않은 이유는 명확하다. 비관적 락은 확실한 대안처럼 보였지만, 실무 환경과 아키텍처의 확장성을 고려했을 때 세 가지 치명적인 걸림돌이 있었다.
1) 데이터베이스 커넥션 점유와 병목 지점 유발
비관적 락은 트랜잭션이 유지되는 동안 DB 락과 DB 커넥션을 함께 쥐고 흔든다.
만약 주문 프로세스 중에 외부 API를 호출하거나 무거운 로직이 얽혀있다면 어떻게 될까?
- [DB Row Lock 획득] ──> 주문서 생성 ──> 결제 승인 외부 API 호출 ──> [PG사 응답 대기 (수 초 소요)]
외부 API 응답을 기다리는 수 초 동안 DB 락과 커넥션이 묶여버린다. 이로 인해 해당 상품을 사려는 다른 사용자는 물론, DB 커넥션 풀(Connection Pool)이 말라버려 시스템 전체가 마비되는 연쇄 장애로 이어질 수 있다. 즉, DB가 시스템의 가장 취약한 병목 지점이 된다.
2) 멀티 인스턴스(수평 확장) 환경에서의 스케일아웃 한계
실무 환경은 단일 서버로 작동하지 않는다.
트래픽에 대응하기 위해 애플리케이션 서버를 여러 대 두는 수평 확장(Scale-out)을 진행한다.
App Server A ──┐
App Server B ──┼──> [ 단일 MySQL 인스턴스 ] (모든 락 관리 부담 집중)
App Server C ──┘
서버 인스턴스가 아무리 늘어나도 결국 락을 관리하는 주체는 단 하나, 중앙의 RDB(MySQL)다. 트래픽이 늘어날수록 DB가 감당해야 하는 락 연산과 트랜잭션 대기 큐가 기하급수적으로 증가하여 인프라 확장 비용이 비효율적으로 커진다.
3) 책임의 분리: RDB는 락 관리자가 아니다
데이터베이스(RDB)의 본질적인 역할은 데이터의 영속성(Persistence) 보장과 복잡한 관계형 쿼리 수행이다. 동시성 제어를 위한 대기 큐 관리와 비즈니스 자원 선점은 RDB에게 너무 무거운 짐이다. 락 관리에 특화된 가벼운 메모리 기반 저장소에게 동시성 제어 역할을 위임하고, RDB는 최종 데이터 저장에만 집중하게 하는 것이 아키텍처 관점에서 훨씬 자연스럽다.
5.3 Redis 기반의 분산 락 (Distributed Lock) 검토
당시 우리 프로젝트에는 인프라 비용을 추가로 들이지 않고도 활용할 수 있는 강력한 무기가 있었다. 이미 로그인 세션 및 Refresh Token 저장을 위해 Redis(Spring Data Redis)를 인프라로 구축해 둔 상태였다. 이미 검증된 고성능 인메모리 저장소가 존재하니, 이를 활용해 애플리케이션 진입 단계에서 분산 락(Distributed Lock)을 구현하는 방향으로 눈을 돌렸다.
- [동시 요청 진입] ──> Redis에서 Key 선점 (락 획득) ──> 안전하게 DB 접근 및 재고 차감 ──> 락 해제
Redis 분산 락을 도입하면 트래픽이 DB에 직접 부딪히기 전에 애플리케이션 레이어와 인메모리 레이어 사이에서 먼저 거르고 정렬할 수 있다. DB는 락 경쟁 없이 락을 획득한 단 하나의 안전한 트랜잭션만 처리하면 된다.
1) Redis 분산 락을 선택한 결정적 이유
내가 지키고자 했던 핵심 가치는 '데이터베이스 시스템의 안정성'과 '재고라는 비즈니스 자원의 올바른 소진'이었다. 우리가 원한 시나리오는 기술적 한계로 84명이 튕겨 나가는 낙관적 락의 모습이 아니었다. 100명이 동시에 진입하더라도 순서대로 줄을 세워, 정확히 10명은 성공시키고 나머지 90명에게는 "재고가 부족합니다"라는 비즈니스 실패(ProductException)를 보여주는 것이었다.
- [낙관적 락] : 100명 진입 ──> 기술적 충돌 에러로 84명 실패 (남은 재고가 있어도 튕김)
- [Redis 분산 락]: 100명 진입 ──> 순서대로 정렬 ──> 10명 안심 성공 ──> 90명은 매진 안내 (비즈니스 실패)
기술적인 예외 상황을 사용자에게 전가하지 않고 비즈니스 규칙 안에서 우아하게 실패를 처리하려면 Redis 분산 락이 가장 완벽한 해답이었다.
2) 동시성 제어 전략 최종 비교 및 선택
세 가지 선택지의 특징을 요약하면 다음과 같다.
| 제어 방식 | 관리 주체 | 핵심 메커니즘 | 고경합 환경에서의 문제점 | 비즈니스 적합도 |
| Optimistic Lock | 애플리케이션 | 버전을 통한 사후 충돌 감지 |
대량의 버전 충돌 예외 발생, 재고 유실 현상 |
❌ (선착순 불가) |
| Pessimistic Lock | 데이터베이스(RDB) | DB Row 익스클루시브 락 |
커넥션 고갈 위험, DB 병목 유발 |
🔺 (안정성 위험) |
| Distributed Lock | 인메모리(Redis) | 진입 전 Redis Key 선점 |
락 획득 대기 및 타임아웃 처리 필요 |
⭕ (고경합 선착순 최적) |
3) 최종 의사결정
우리 프로젝트의 요구사항인 '고경합 환경에서의 상품 재고 차감', '선착순 주문 처리', 그리고 향후 확장될 '선착순 쿠폰 발급 및 중복 결제 방지' 같은 기능까지 고려했을 때, 최종 승자는 Redis Distributed Lock이었다. 이제 도구를 정했으니 다음 과제는 "어떻게 구현할 것인가"였다. 우리는 Redis를 활용한 분산 락 구현체로 Spring Data Redis(Lettuce)를 이용해 직접 스핀 락을 구현하는 대신, Redisson 라이브러리를 채택하기로 했다. 다음 장에서는 Lettuce의 한계와 Redisson을 선택한 기술적 이유(Pub/Sub, Watch Dog, tryLock 메커니즘)를 심도 있게 다루도록 한다.