
1. Redis Distributed Lock 구현 전략
1) Redis를 사용한다고 모두 같은 분산 락은 아니다
Redis 기반의 분산 락을 도입하기로 결정한 후, 곧바로 두 번째 설계적 갈림길에 마주쳤다. "이 분산 락을 어떤 방식으로 구현할 것인가?"에 대한 문제였다. 가장 먼저 떠오르는 직관적인 방법은 이미 프로젝트에 내장되어 있는 Spring Data Redis의 RedisTemplate을 이용해 직접 락 메커니즘을 빌드하는 것이다. 흔히 알려진 SETNX (Set if Not Exists) 명령어 구조다.
// Spring Data Redis를 활용한 원시적인 락 획득 시도 (SET NX EX)
Boolean acquired = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "LOCK", Duration.ofSeconds(3));
if (Boolean.TRUE.equals(acquired)) {
// 락 획득 성공: 비즈니스 로직(재고 차감) 수행
} else {
// 락 획득 실패: 스핀 락(Spin Lock) 형태로 재시도 루프를 돌거나 에러 처리
}
인터넷의 수많은 튜토리얼이 이 `SET NX EX`방식을 가리키고 있었기에 처음에는 이 정도로도 충분해 보였다. 그러나 대규모 트래픽이 맞물리는 분산 환경을 시뮬레이션하며 엣지 케이스(Edge Case)를 따져보기 시작하자, 직접 구현한 원시적인 락이 품고 있는 치명적인 함정들이 드러났다.
1.1 단순 구현이 놓치는 첫 번째 함정: 락 소유권 유실과 '남의 락 해제'
가장 먼저 발생할 수 있는 결함은 '락 소유권(Ownership)'의 모호함이다. 다음과 같은 타임라인을 가정해 보자.

여기서 대참사가 발생한다. Server A가 마지막에 호출한 `delete()`는 자기가 잡았던 락이 아니라, 현재 Server B가 획득해서 정상적으로 사용 중인 락을 임의로 지워버리게 된다. 락이 예기치 않게 해제되면서 뒤이어 대기하던 Server C, D가 동시에 진입하게 되고, 분산 락을 걸었음에도 동시성 정합성이 통틀어 깨지는 현상이 발생한다.
1.2 두 번째 함정: 원자성(Atomicity)이 결여된 소유권 검증
"남의 락을 해제하는 문제"를 막기 위해,
흔히 락의 Value에 고유한 값(예: UUID나 Thread ID)을 저장하고 해제할 때 검증하는 로직을 추가한다.
Key: lock:product:1 | Value: server-a-thread-123
락을 풀기 전에 `if (현재_UUID == Redis_Value_UUID)`를 검사하고, 일치할 때만 삭제(delete)하는 방식이다.
하지만 이 수정 역시 '검증'과 '삭제'라는 두 행위가 분리되어 있기 때문에 또 다른 경쟁 상태를 낳는다.
- Server A: Redis에 저장된 UUID가 본인 것임을 확인 (검증 성공)
- [찰나의 순간: Server A의 락 TTL 만료 및 자동 삭제]
- Server B: 즉시 새로운 락 획득 완료
- Server A: 검증을 미리 통과했으므로 delete(lockKey) 수행 ──> Server B의 락 삭제 완료
결국 검증과 삭제 과정이 단 하나의 쿼리처럼 묶여서 실행되는 원자성(Atomicity)을 보장받지 못하면 이 함정에서 벗어날 수 없다. 이를 안전하게 처리하려면 Redis 내부에서 연산을 하나로 묶어주는 랭귀지인 루아 스크립트(Lua Script)를 직접 작성해 애플리케이션에서 주입해야 한다.
1.3 세 번째 함정: 예측 불가능한 비즈니스 타임아웃과 TTL의 딜레마
가장 풀기 어려운 난제는 락의 유효 시간(TTL, Time To Live) 설정이다.
만약 가용 커넥션 고갈, JVM의 Stop-the-world(GC), 혹은 예기치 못한 네트워크 지연으로 인해 평소 0.1초 걸리던 재고 차감 로직이 순간적으로 5초가 걸렸다고 가정해 보자. 락의 TTL이 3초였다면, 로직이 다 끝나기도 전에 락이 먼저 해제되어 동일 자원에 복수의 서버가 접근하는 최악의 동시성 장애가 발생한다. 그렇다고 락 선점 시간(TTL)을 30초, 1분 처럼 과도하게 길게 잡으면, 정말로 특정 서버가 다운되었을 때 해당 락이 풀리지 않아 대기 중인 모든 사용자의 주문 프로세스가 롱 타임아웃으로 묶여버리는 트레이드오프가 발생한다.
1.4 직접 구현은 배보다 배꼽이 더 크다
결국, 상용 환경에서 안전하게 동작하는 분산 락을 자력으로 만들려면 다음의 기능을 전부 완벽하게 코드로 구현해 내야 한다.
- 락 획득 실패 시 무의미한 주기적 요청으로 Redis 서버 부하를 높이는 스핀 락(Spin Lock) 구조 지양 및 효율적인 재시도(Retry) 매커니즘 구현
- 루아 스크립트를 통한 소유권 검증 및 삭제 연산의 원자성 보장
- 비즈니스 실행 시간에 비례해 락 만료 시간을 동적으로 연장해 주는 스레드 구현
- 예외 발생 시의 철저한 자원 반납(Unlock) 보장
이 모든 요소를 밑바닥부터 다듬는 것은 "상품 재고 관리"라는 우리 비즈니스 도메인 범주를 넘어서는 일이며, 자칫 분산 락 프레임워크 자체를 개발하는 형태로 프로젝트의 본질이 전도될 위험이 컸다. 이에 따라 우리는 이미 수많은 글로벌 서비스의 고경합 환경에서 검증된 자바 오픈소스 라이브러리인 Redisson을 채택하기로 결정했다.
2. 구원투수: Redisson의 분산 락 매커니즘
Redisson은 단순한 Redis 클라이언트를 넘어, Redis 위에서 작동하는 고수준의 분산 비즈니스 객체들을 제공한다.
밤새 고민했던 분산 환경의 난제들을 이미 완벽한 아키텍처로 해결해 두었다.
1) Pub/Sub 기반의 락 획득 대기 (네트워크 트래픽 최적화)
Lettuce 등을 활용한 스핀 락 방식은 락을 얻을 때까지 "락 비었나요?"라는 요청을 지속적으로 Redis에 날려 CPU와 네트워크 자원을 갉아먹는다. 반면 Redisson은 Redis의 Pub/Sub(발행/구독) 메커니즘을 활용한다. 락을 획득하지 못한 스레드는 대기 큐에 들어가 Redis의 특정 채널을 구독한 채 대기하고, 기존 락을 쥔 스레드가 락을 해제하며 "락 반납 완료" 신호를 발행(Publish)하면 그제야 락 획득을 시도한다. Redis 서버가 받는 부하를 획기적으로 줄여주는 구조다.
2) 락 유효 시간 자동 연장: 왓치독(Watch Dog) 기능
Redisson은 락의 TTL 문제를 'Watch Dog'이라 불리는 내부 스레드를 통해 우아하게 해결한다. 개발자가 락의 만료 시간을 별도로 지정하지 않으면 기본값(`30`초)으로 락을 잡은 뒤, 비즈니스 로직이 계속 실행 중이라면 왓치독이 백그라운드에서 타이머를 돌리며 락의 만료 시간을 주기적으로 자동 연장(Renewal)해 준다. 덕분에 로직이 지연되더라도 락이 도중에 증발하여 동시성 정합성이 깨질 위험이 원천 차단된다.
3) 직관적인 인터페이스와 캡슐화
개발자가 마주하는 코드는 복잡한 루아 스크립트나 UUID 비교 연산이 아니다.
단 몇 줄의 직관적인 객체 지향 코드로 완벽한 분산 락을 구동할 수 있다.
RLock lock = redissonClient.getLock("lock:product:" + productId);
try {
// tryLock(대기시간, 만료시간, 단위)
// Watch Dog을 활성화하기 위해 만료시간은 명시하지 않거나 내부 설정을 따른다.
boolean available = lock.tryLock(5, TimeUnit.SECONDS);
if (available) {
// 비즈니스 로직 수행 (안전한 재고 예약)
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
if (lock.isHeldByCurrentThread()) { // 소유권 검증이 내장된 안전한 언락
lock.unlock();
}
}
2.1 인프라 레이어의 역할 분리 결정
최종적으로 우리 프로젝트는 성능 최적화와 결합도 분리를 위해 Redis를 활용하는 인프라 레이어의 역할을 다음과 같이 이원화했다.
- Spring Data Redis (Lettuce)
- 주요 역할: 단순 Key-Value 데이터 저장 및 조회
- 대상 도메인: JWT / Refresh Token 저장, 유저 세션 관리 등
- Redisson
- 주요 역할: 고경합 비즈니스 자원의 동시성 제어
- 대상 도메인: 상품 재고 분산 락, 선착순 진입 순서 보장
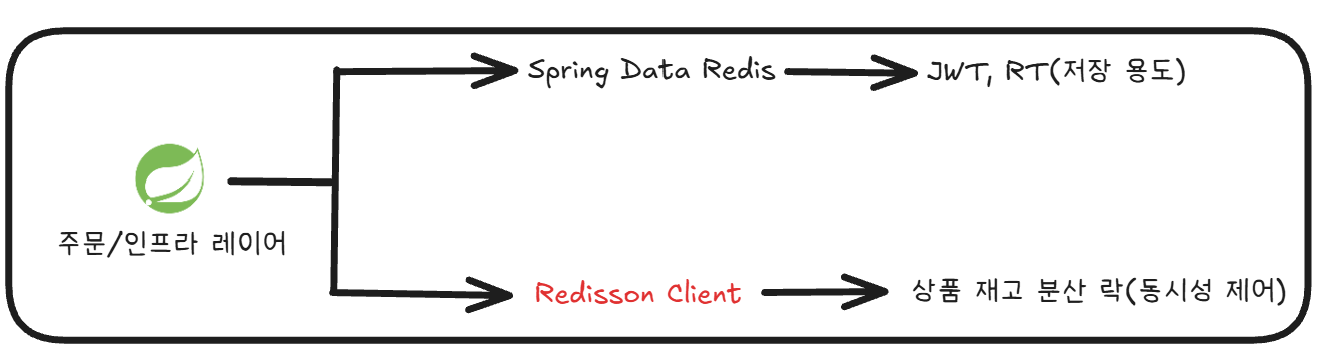
인프라의 성격을 명확히 분리함으로써 데이터 저장소로서의 성능과 분산 제어 락 도구로서의 안정성을 동시에 챙길 수 있게 되었다.
그렇다면 이 강력한 Redisson 분산 락을 실제 우리 Spring 부트 환경의 애플리케이션 비즈니스 코드에 어떻게 녹여냈을까? 비즈니스 로직과 인프라 코드가 지저분하게 뒤섞이지 않도록 깔끔하게 설계한 '분산 락 실행기(Lock Executor)' 과정을 구체적으로 살펴보자.
3. DistributedLockExecutor 설계
1) 처음 떠올랐던 직관적인 구현 방식
Redis와 Redisson이라는 명확한 도구를 정한 뒤, 가장 먼저 머릿속에 그린 구현 형태는 단순했다.
락이 필요한 서비스 레이어 내부에서 RedissonClient를 주입받아 직접 제어 구문을 작성하는 방식이었다.
// 주문 생성 서비스 내부에서의 직접적인 락 제어 (초기 안)
public Long createOrder(CreateOrderCommand command) {
String lockKey = "lock:product:" + command.getProductId();
RLock lock = redissonClient.getLock(lockKey);
try {
// 락 획득 시도
if (!lock.tryLock(3, 5, TimeUnit.SECONDS)) {
throw new ProductException(ProductErrorCode.LOCK_ACQUISITION_FAILED);
}
// 핵심 주문 비즈니스 로직 수행
return createOrderService.process(command);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new SystemException(SystemErrorCode.SERVER_ERROR);
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock(); // 락 반납
}
}
}이 코드는 실무에서 정상적으로 돌아간다. 동시성 제어도 원하던 대로 작동한다.
하지만 정상 작동 여부와 별개로, 이 설계는 유지보수 관점에서 심각한 결함을 품고 있었다.
2) 비즈니스 로직 오염과 강한 결합도
위 방식의 가장 큰 한계는 비즈니스 영역과 인프라 영역의 경계가 무너진다는 점이다.
우리가 작성한 서비스의 본질적인 핵심 관심사(Core Concern)는 '상품을 조회하고, 가용 재고를 확인하여, 주문서와 결제 예약을 생성하는 것'이다. 하지만 코드의 절반 이상을 차지하는 것은 `try-catch-finally`, `tryLock`, `isHeldByCurrentThread` 같은 인프라스트럭처 레벨의 공통 관심사(Cross-cutting Concern)다.
- [기존 서비스 내부 흐름]
락 키 생성 -> 락 획득 시도 -> 예외 처리 -> [ 진짜 비즈니스 로직 ] -> 스레드 소유권 검증 -> 락 해제
결과적으로 코드를 읽을 때 주문 흐름이 한눈에 들어오지 않고 락 제어 로직에 시선이 분산된다. 또한, 향후 재고가 아닌 '쿠폰 발급'이나 '선착순 이벤트' 등 다른 도메인에 분산 락을 도입할 때마다 똑같은 인프라 코드가 수없이 복사·붙여넣기되어 시스템 전반의 결합도가 극도로 높아지는 위험이 있었다.
3) 함수형 인터페이스를 활용한 추상화 분리
비즈니스 로직을 오염시키지 않으면서 분산 락을 우아하게 재사용하기 위해 추상화 레이어를 도입하기로 했다. 서비스 계층은 오직 "무엇을 할 것인가(What)"에만 집중하고, 락을 획득하고 해제하는 "어떻게 처리할 것인가(How)"의 메커니즘은 별도의 컴포넌트에 격리하는 구조다. 이를 위해 자바의 함수형 인터페이스인 `Supplier<T>`를 활용하여 DistributedLockExecutor 인터페이스를 설계했다.
public interface DistributedLockExecutor {
/**
* 지정된 Lock Key로 분산 락을 획득한 후, 안전하게 비즈니스 태스크를 실행한다.
*/
<T> T execute(String lockKey, Duration waitTime, Duration leaseTime, Supplier<T> task);
}
이 인터페이스의 책임은 단 하나다. "락을 안전하게 확보하고, 넘겨받은 행위(Task)를 실행한 뒤, 락을 확실하게 반납하는 것"이다.
3.1 Redisson 기반 구현체 정밀 분석
인터페이스의 명세를 바탕으로 구현한 RedissonDistributedLockExecutor의 핵심 구조는 다음과 같다.
@Component
@RequiredArgsConstructor
public class RedissonDistributedLockExecutor implements DistributedLockExecutor {
private final RedissonClient redissonClient;
@Override
public <T> T execute(String lockKey, Duration waitTime, Duration leaseTime, Supplier<T> task) {
RLock lock = redissonClient.getLock(lockKey);
try {
// 지정된 시간만큼 락 획득을 시도한다.
boolean acquired = lock.tryLock(waitTime.toSeconds(), leaseTime.toSeconds(), TimeUnit.SECONDS);
if (!acquired) {
// 상위 레이어에서 핸들링할 수 있도록 커스텀 예외 투척
throw new ProductException(ProductErrorCode.CONCURRENCY_CONFLICT);
}
// 락 획득 성공 시 전달받은 비즈니스 로직 수행
return task.get();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new SystemException(SystemErrorCode.SERVER_ERROR);
} finally {
// 안전한 락 해제 검증
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
1) 왜 무한 대기(lock()) 대신 tryLock()을 선택했는가?
Redisson 클라이언트는 락을 잡을 때 무한정 대기하는 `lock.lock()` 메서드도 제공한다. 하지만 우리 시스템의 재고 차감 도메인에서는 무한 대기 방식이 치명적인 병목을 만들 수 있다. 만약 앞선 트랜잭션이 네트워크 장애나 외부 요인으로 인해 락을 쥔 채 비정상적으로 멈춰버린다면 어떻게 될까? 뒤이어 들어오는 수백, 수천 개의 주문 스레드가 동시 다발적으로 락을 얻기 위해 무한정 대기(Blocking) 상태로 굳어버린다. 이는 톰캣(Tomcat) 스레드 풀 고갈로 이어져 시스템 전체가 먹통이 되는 연쇄 장해를 유발한다.
고경합 선착순 커머스 환경에서는 '빠른 성공(Fast Success)'만큼이나 '빠른 실패(Fast Failure)'를 받아들여 시스템 인프라를 보호하는 것이 중요하다. 그렇기에 대기 시간 한계선을 설정할 수 있는 `tryLock(waitTime, leaseTime)`을 선택했다. 우리 프로젝트는 대기 시간을 `3`초로 제한하여, 피크 트래픽 상황에서도 시스템이 롱 타임아웃에 빠지지 않고 유연하게 제어되도록 설계했다.
2) isHeldByCurrentThread()를 통한 안전한 언락(Unlock)의 이유
`finally` 블록에서 락을 해제할 때 단순히 `lock.unlock()`만 호출하면 예기치 못한 동시성 에러를 마주할 수 있다. 비즈니스 로직 수행 시간이 설정한 임계치(Lease Time)보다 오래 걸려 락이 이미 만료되었거나, 네트워크 타임아웃으로 인해 현재 스레드가 락의 소유권을 상실한 상태일 수 있다. 이때 소유권이 없는 스레드가 무작정 `unlock()`을 호출하면 자바 표준 스펙상 `IllegalMonitorStateException`이 발생한다. 이 예외는 트랜잭션의 정상적인 마무리(롤백 혹은 커밋)를 방해하고 로그를 오염시키므로, 반드시 `lock.isHeldByCurrentThread()`를 통해 현재 실행 중인 스레드가 해당 락의 정당한 소유자인지 물리적으로 검증한 후 해제하도록 안전장치를 구축했다.
3) 구조 개선 후 서비스 레이어의 변화
추상화 실행기(DistributedLockExecutor)를 도입한 결과, 주문 서비스 코드는 극적인 다이어트에 성공했다.
개선 후 주문 서비스 코드는 다음과 같다.
@Service
@RequiredArgsConstructor
public class CreateOrderService {
private final DistributedLockExecutor lockExecutor;
private final CreateOrderProcessor createOrderProcessor;
public Long create(CreateOrderCommand command) {
String lockKey = "lock:product:" + command.getProductId();
// 인프라 코드는 실행기에게 위임하고, 서비스는 행위(Task)만 주입한다.
return lockExecutor.execute(
lockKey,
Duration.ofSeconds(3),
Duration.ofSeconds(5),
() -> createOrderProcessor.process(command) // 실제 비즈니스 로직
);
}
}
이제 주문 서비스는 락을 어떻게 획득하고 풀지 전혀 알 필요가 없다.
코드가 간결해졌으며, 비즈니스 흐름이 명확히 드러나 가독성과 유지보수성이 비약적으로 상승했다.
4)하지만, 락과 트랜잭션의 '타임라인 꼬임'이라는 거대한 복병
분산 락 추상화를 멋지게 성공시키고 동시성 테스트를 돌리려는 순간, 훨씬 더 정밀하고 치명적인 아키텍처적 결함이 수면 위로 올라왔다. 바로 "Redisson 분산 락의 해제 시점"과 "Spring `@Transactional`의 DB 커밋 시점"이 일치하지 않아 발생하는 데이터 레이스(Data Race) 문제였다.
기존의 주문 로직은 단일 메서드에 `@Transactional`과 락 실행기가 한데 묶여 있었다. 이 구조에서는 락이 먼저 풀려버린 뒤에 뒤늦게 DB 커밋이 완료되는 짧은 찰나의 틈새(Gap)가 생긴다. 이 미세한 틈을 타고 다른 스레드가 침투하면, 변경 사항이 아직 반영되지 않은 올드 버전의 재고를 DB에서 읽어가게 되므로 분산 락을 걸었음에도 초과 판매가 발생하는 대참사가 벌어질 수 있었다. 이 인프라적 모순을 완벽히 격리하기 위해, 우리는 주문 생성 단계를 락을 관리하는 서비스(CreateOrderService)와 실제 트랜잭션을 열어 재고를 차감하는 프로세서(CreateOrderProcessor)로 한 단계 더 쪼개는 대대적인 리팩토링을 단행하게 되었다. 분산 락을 도입할 때 수많은 개발자가 가장 많이 실수하는 영역이자, 이번 프로젝트에서 가장 핵심적인 개선 작업이었던 '락과 트랜잭션의 생명주기 동기화 전략'을 깊이 있게 파헤쳐 보자.
4. Transaction과 Distributed Lock의 경계
1) 처음에는 단순하게 접근
분산 락 추상화 컴포넌트인 DistributedLockExecutor를 완성한 후, 기존 주문 생성 서비스에 적용하는 단계로 넘어갔다. 기존의 주문 로직은 하나의 거대한 데이터베이스 트랜잭션(`@Transactional`) 안에서 상품 조회, 재고 예약, 주문 저장을 한 번에 처리하고 있었다. 초기에는 기존 메서드 내부에 락 실행기를 그대로 집어넣는 방식을 고려했다.
// @Transactional과 분산 락이 한 메서드에 묶인 구조 (위험한 초기 안)
@Transactional
public Long create(CreateOrderCommand command) {
String lockKey = "lock:product:" + command.getProductId();
// 락 획득 후 내부 비즈니스 로직(익명 함수) 수행
return lockExecutor.execute(
lockKey, waitTime, leaseTime,
() -> createInternal(command)
);
}
코드 가독성도 좋고, 락 분리도 깔끔하게 끝난 것처럼 보였다. 하지만 이 구조는 멀티스레드 고경합 환경에서 분산 락을 걸었음에도 데이터 정합성이 처참하게 깨질 수 있는 치명적인 아키텍처적 불일치를 내포하고 있었다.
2) Spring Transaction은 언제 Commit될까?
이 문제를 이해하려면 Spring AOP 기반의 `@Transactional` 프록시 메커니즘을 정확히 파악해야 한다. 수많은 개발자가 메서드가 끝나는 대괄호(`{}`) 시점에 DB 커밋이 완료된다고 착각하지만, 실제 내부 프록시 인터셉터의 동작 타이림 체인은 완전히 다르다. 위의 위험한 초기 안 구조를 타임라인으로 풀어 쓰면 다음과 같은 순서로 실행된다.
- [프록시] `@Transactional` 인터셉터 동작 (트랜잭션 시작)
- [서비스] `create()` 메서드 진입
- [실행기] Redis 분산 락 획득 성공
- [도메인] 비즈니스 로직 수행 (재고 예약 & 주문 저장)
- [실행기] `task.get()` 종료 및 `finally` 블록 진입 ──> [Redis 분산 락 해제 (Unlock)]
- [서비스] `create()` 메서드 종료 (컨트롤 복귀)
- [프록시] `@Transactional` 인터셉터 종료 ──> [데이터베이스 커밋 (DB Commit)]
여기서 가장 주목해야 할 위험 구간은 바로 5번과 7번 사이의 간극이다. 시스템 내부적으로 "분산 락은 이미 해제되었는데, 정작 데이터베이스에는 변경 사항이 반영되지 않은(Commit 전) 찰나의 진공 상태"가 발생하게 된다.
3) Lock이 먼저 풀릴 때 발생하는 데이터 레이스(Data Race)
이 미세한 타임라인의 틈새가 고경합 환경과 만나면 어떤 대참사로 이어지는지,
가용 재고가 단 1개 남은 한정판 상품 시나리오를 통해 뜯어보자.

스레드 A가 락을 풀자마자 기다리던 스레드 B가 번개처럼 락을 가로채어 DB를 조회한다. 하지만 스레드 A의 트랜잭션 커밋 쿼리가 데이터베이스 네트워크를 타고 반영되기 직전이기 때문에, 스레드 B는 여전히 재고가 1개 남아있는 스냅샷을 읽게 된다. 결국 두 스레드 모두 정상적인 비즈니스 검증을 통과하게 되고, 최종적으로 재고가 마이너스로 떨어지는 초과 판매(Overselling)가 재발한다. 비용을 들여 분산 락 시스템을 구축해 놓고도 무력화되는 허무한 순간이다.
4.1 해결 공식: 락의 범위는 트랜잭션 범위보다 넓어야 한다
이 문제를 해결하기 위한 대원칙은 단순하다. 동시성을 제어하는 분산 락의 생명주기는 반드시 데이터베이스 트랜잭션의 시작보다 먼저 열리고, 트랜잭션 커밋(영속화)이 완전히 끝난 후에 닫혀야 한다.

이 순서가 보장되어야만, 다음 스레드가 락을 쥐고 DB를 조회했을 때 앞선 스레드가 커밋한 최신 재고 데이터 상태를 안전하게 읽어갈 수 있다.
4.2 대안 검토 및 의사결정
이 올바른 수명주기 타임라인을 확보하기 위해 두 가지 대안을 검토했다.
방법 1) TransactionSynchronizationManager 활용
Spring이 제공하는 트랜잭션 동기화 매니저를 사용하여 커밋이 완전히 끝난 후 동작하는 리스너(afterCommit()) 시점에 락을 해제하도록 이벤트를 바인딩하는 방식이다.
- 평가: 기술적으로 매우 정교해 보이지만, 코드가 스프링 로우 레벨 API에 강하게 종속된다. 결정적으로 트랜잭션이 정상 커밋될 때뿐만 아니라 예외로 인한 롤백(Rollback) 상황, 인프라 장해 상황에서의 예외 전파 구조까지 전부 수동으로 핸들링해야 하므로 코드가 비대해지고 오버엔지니어링이 될 확률이 높았다.
방법 2) 트랜잭션 경계 분리 (구조적 격리)
락을 관리하는 인프라성 컴포넌트와 실제 데이터베이스 트랜잭션을 실행하는 비즈니스 컴포넌트를 두 개의 독립된 스프링 빈(Bean)으로 수평 분리하는 방식이다.
- 평가: 스프링의 선언적 트랜잭션 구조를 그대로 활용할 수 있어 가장 직관적이고 안전하며,
코드 가독성 또한 명확해지므로 이 방식을 최종 선택했다.
4.3 CreateOrderService와 CreateOrderProcessor의 탄생
의사결정에 따라 기존의 CreateOrderService 하나로 처리하던 구조를 역할과 책임에 따라 상위 서비스(Service)와 하위 프로세서(Processor)의 2레이어로 쪼개는 리팩토링을 단행했다.
1) CreateOrderService (외곽 레이어: 인프라 및 동시성 제어)
`@Transactional` 어노테이션이 없다. 오직 Redis 분산 락을 획득하고 해제하는 뼈대 아키텍처 역할만 수행한다.
@Service
@RequiredArgsConstructor
public class CreateOrderService {
private final DistributedLockExecutor lockExecutor;
private final CreateOrderProcessor createOrderProcessor; // 하위 트랜잭션 빈 주입
public Long create(CreateOrderCommand command) {
String lockKey = "lock:product:" + command.getProductId();
// 1. 락을 먼저 획득한 채로 내부 진입
return lockExecutor.execute(
lockKey, Duration.ofSeconds(3), Duration.ofSeconds(5),
() -> createOrderProcessor.process(command) // 2. 트랜잭션이 있는 하위 프로세서 호출
);
}
}
2) CreateOrderProcessor (핵심 레이어: 비즈니스 및 데이터베이스 트랜잭션)
전체 메서드가 `@Transactional` 환경에서 실행된다. 락의 엄호 아래서 순수하게 재고 불변식을 검증하고 주문 데이터를 영속화한다.
@Component
@RequiredArgsConstructor
public class CreateOrderProcessor {
private final ProductStockRepository productStockRepository;
private final OrderRepository orderRepository;
@Transactional // 여기서 새 트랜잭션이 시작되고 메서드 종료 시 완전히 커밋된다.
public Long process(CreateOrderCommand command) {
// 상품 조회 -> 재고 예약(reserve) -> 주문서 저장
// ... 순수 비즈니스 로직 수행
return order.getId();
}
}
3) 최종 정렬된 올바른 실행 흐름
이 구조적 분리를 통해 우리가 그토록 원했던 안전한 타임라인이 자연스럽게 완성되었다.
- [사용자 주문 요청]: CreateOrderService 진입 (락 관리자)
- Redis Distributed Lock 획득 성공 (엄호 시작)
- CreateOrderProcessor.process() 호출: [Spring Proxy 가동: DB 트랜잭션 시작]
- 비즈니스 로직 수행 (가용 재고 조회 및 reserve() 호출)
- 주문 및 재고 데이터 반영 완료: [Spring Proxy 가동: 데이터베이스 커밋 완료 및 트랜잭션 종료]
- CreateOrderProcessor 종료 (Service 레이어로 제어권 반환)
- Redis Distributed Lock 안전하게 해제 (Unlock)
락 획득(`Lock`) → 트랜잭션 시작(`Tx`) → 데이터 반영 후 커밋 완료(`Commit`) → 락 해제(`Unlock`)의 철벽 순서가 프록시 전파 특성에 의해 완벽하게 보장된다.
4) 아키텍처 분리가 가져다준 놀라운 나비효과
단지 락과 트랜잭션의 충돌을 피하기 위해 선택한 분리 구조였지만,
객체지향 설계와 시스템 확장성 관점에서 기대 이상의 보너스 효과들을 얻을 수 있었다.
1. 단일 책임 원칙(SRP)의 극대화
- CreateOrderService: 오직 동시성 제어 및 외부 인프라스트럭처(Redis) 조율에만 책임을 진다.
- CreateOrderProcessor: Redis의 존재를 전혀 모른 채, 오직 도메인 비즈니스 무결성과 영속성 처리에만 집중한다.
2. 테스트 용이성 (Testability)의 비약적 상승
프로세서가 인프라 락 필터와 결합하지 않으 무거운 내장 Redis 인프라 없이도 Mock 객체와 순수 자바 코드를 활용해 초고속 단위 테스트(CreateOrderProcessorTest)를 작성할 수 있게 되었다. 반면 외곽의 CreateOrderServiceConcurrenyTest에서는 실제 Redis 분산 환경에서의 경쟁 상태만 벼려진 형태로 집중 검증한다. 테스트의 목적과 격리 수준이 맑아진 것이다.
3. 검증된 아키텍처 패턴의 자산화
이 '서비스-프로세서' 레이어 분리 모델은 향후 추가될 '선착순 한정 쿠폰 발급 시스템', '동일 주문 중복 결제 차단 이중 락', '이벤트 선착순 응모 기획' 등 대규모 동시성 제어가 필요한 모든 고경합 도메인에 복사기처럼 그대로 이식할 수 있는 우리 팀의 핵심 아키텍처 자산이 되었다.
4.4 최종 시스템 아키텍처 토폴로지
결국 이번 동시성 개선 작업의 진정한 가치는 단순히 Optimistic Lock을 Redis Lock으로 치환한 기술 교체에 있지 않았다. 고경합 비즈니스의 특성을 깊이 이해하고, 비즈니스 도메인 규칙(ProductStock) -> 외부 인프라 제어(DistributedLockExecutor) -> 데이터베이스 트랜잭션 경계(Processor)를 유기적으로 엮어낸 전면적인 구조 재설계의 결과물이다. 최종적으로 완성된 우리 프로젝트의 클라이언트 요청 처리 파이프라인은 다음과 같다.

5. 다중 상품 주문과 Deadlock 방지 전략
1) 단일 상품 주문은 생각보다 쉽다
이전 장까지 설계한 Redis 분산 락 구조는 하나의 주문에 하나의 상품만 포함된다는 가정이 깔려 있었다.
단일 상품 주문의 제어 흐름은 아래와 같이 직관적이며 복잡할 이유가 없다.
- [단일 상품 주문 흐름]
Lock(상품A) 획득 ──> 가용 재고 예약 ──> 주문서 영속화(Commit) ──> Unlock(상품A) 반납
하지만 실제 이커머스 환경에서 사용자는 장바구니를 통해 상품 A, 상품 B, 상품 C를 한 번에 담아 결제하는 '다중 상품 주문'을 빈번하게 요청한다. 동시성 제어의 진정한 난이도는 제어해야 할 자원이 2개 이상으로 늘어나는 다중 상품 주문 도메인에서부터 시작된다.
5.1 다중 상품 주문의 치명적인 함정: 교착 상태(Deadlock)
복수의 자원에 대해 제어권을 얻어야 할 때, 각 트랜잭션이 락을 획득하는 순서가 제각각 다르면 어떤 일이 벌어질까?
아주 흔하게 발생하는 교착 상태(Deadlock) 시나리오를 살펴보자.
- 상황: 두 명의 사용자가 서로 다른 상품 조합을 동시에 주문한다.
- 사용자 A: [상품 1]과 [상품 2]를 동시에 주문
- 사용자 B: [상품 2]와 [상품 1]을 동시에 주문
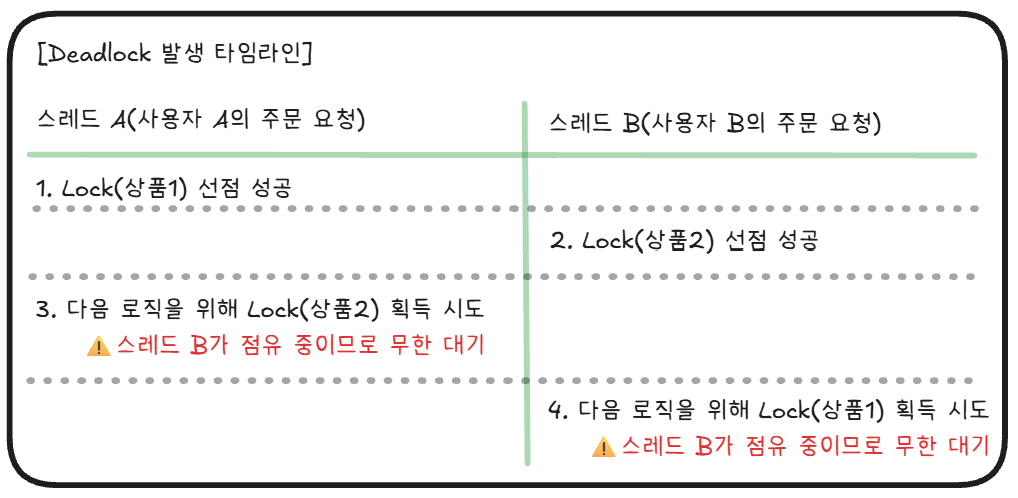
결과는 참사다. 스레드 A는 스레드 B가 가진 락이 풀리기만을 기다리고, 스레드 B는 스레드 A가 가진 락이 풀리기만을 기다린다.
두 스레드가 서로의 자원을 물고 영원히 대기하는 교착 상태(Deadlock)에 빠지게 된다.
1) 데드락이 시스템에 미치는 영향
데드락이 위험한 이유는 시스템 자원을 고갈시키는 가장 빠른 지름길이기 때문이다.
- 비즈니스 마비: 교착 상태에 빠진 트랜잭션은 재고 차감도, 주문 생성도 하지 못하고 멈춰 선다.
- 인프라 붕괴: 락을 쥐고 대기하는 스레드가 증가할수록 애플리케이션의 WAS 스레드 풀과 Redis 커넥션 풀이 순식간에 마비된다. 대규모 트래픽 환경에서 데드락 방지 전략이 없으면 단 몇 건의 꼬인 요청만으로 전체 서비스가 완전히 다운되는 장해로 이어진다.
따라서 여러 자원의 락을 동시에 획득해야 할 때는 '락을 획득하는 순서의 표준화'가 무조건 보장되어야 한다.
2) 해결 전략: 전역 순서 보장 (Global Ordering)
데드락을 원천 차단하는 가장 확실한 방법이 있다.
"모든 스레드가, 어떤 조합으로 주문하든, 항상 정해진 규칙에 따라 동일한 순서로만 락을 획득하게 강제하는 것"
내 프로젝트는 시스템 전반에서 유일성과 순서 비교가 가능한 데이터인 상품 ID(productId) 기준의 오름차순 정렬 규칙을 전역 순서(Global Ordering) 전략으로 채택했다. 전역 순서 정렬 적용 코드이다.
List<Long> productIds = command.orderLines().stream()
.map(CreateOrderCommand.OrderLineCommand::productId)
.distinct() // 중복 상품 제거
.sorted() // 상품 ID 기준 오름차순 정렬 (핵심!)
.toList();
이 규칙을 적용하면 사용자가 상품을 어떻게 섞어서 주문하든 시스템 내부에서는 무조건 일관된 순서로 락을 요청하게 된다.
- [사용자 A의 주문]: 상품 5, 상품 1, 상품 3 ── 정렬 ──> [락 획득 순서]: 상품 1 ─> 상품 3 ─> 상품 5
- [사용자 B의 주문]: 상품 3, 상품 5, 상품 1 ── 정렬 ──> [락 획득 순서]: 상품 1 ─> 상품 3 ─> 상품 5
두 스레드가 동일한 방향 순서로만 자원을 확보해 나가기 때문에, 한 스레드가 앞선 자원(상품 1)을 선점하면 뒤이은 스레드는 첫 단계에서부터 정렬되어 대기한다. 이로써 서로가 서로의 자원을 교차해서 무는 상황 자체가 물리적으로 불가능해지며, 데드락은 100% 원천 차단된다.
3) 왜 .distinct()를 통한 중복 제거가 필수적이었을까?
주문 요청서에는 하나의 상품이 여러 개의 선택 옵션(예: 상품 1 x 2개, 상품 1 x 3개)으로 나뉘어 중복된 상품 ID로 들어올 수 있다.
만약 중복 제거 없이 정렬만 수행하면 한 트랜잭션 내부에서 동일한 자원에 대해 Lock(상품1) ─> Lock(상품1)을 연속으로 요청하게 된다. 물론 Redisson은 동일 스레드가 락을 중복으로 획득할 수 있는 재진입 락(Reentrant Lock)을 지원하므로 즉시 에러가 나거나 데드락이 걸리지는 않는다. 하지만 이는 Redis 서버를 향해 불필요한 네트워크 비용과 락 연산 오버헤드를 추가로 발생시키는 행위다. 고경합 환경일수록 인프라에 가해지는 무의미한 부하를 최소화해야 하므로, .distinct() 연산자를 통해 타겟 상품 ID 목록을 깔끔하게 단축시킨 후 락 프로세스에 진입하도록 설계했다.
4) 동적 자원 처리를 위한 재귀적 락(Recursive Lock) 설계
다중 상품 주문에서 마주한 또 다른 기술적 과제는 "사용자가 상품을 몇 개나 주문할지 컴파일 시점에 알 수 없다"는 점이었다.
누군가는 2개를, 누군가는 10개를 주문할 수 있다.
// 이런 식의 하드코딩된 구조로는 동적 자원을 제어할 수 없다.
lock1.tryLock();
lock2.tryLock();
상품 개수에 유연하게 대응하면서,
정렬된 순서대로 정확히 락을 획득하고 풀기 위해 재귀적 호출 구조(Recursive Stack)를 도입했다.
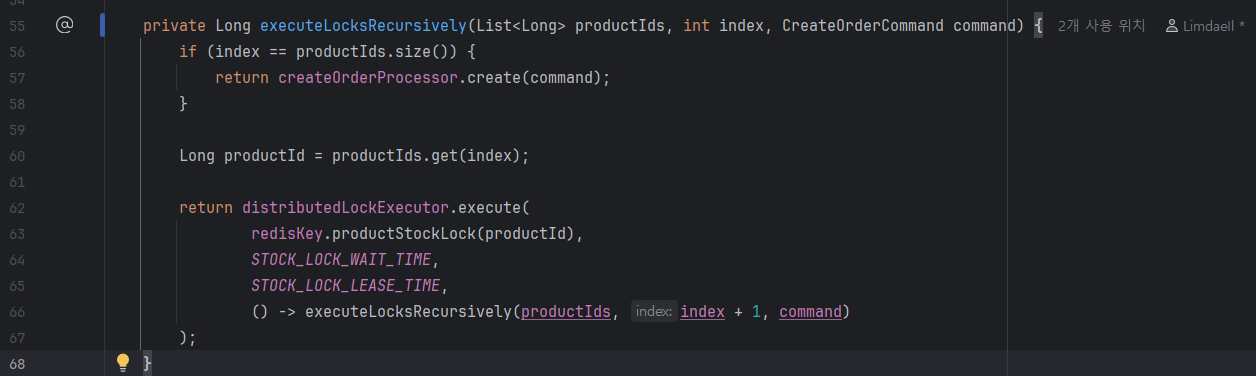
private Long executeLocksRecursively(List<Long> productIds, int index, CreateOrderCommand command) {
// [종료 조건] 모든 상품의 락을 정해진 순서대로 전부 확보했다면, 드디어 핵심 비즈니스로 진입
if (index == productIds.size()) {
return createOrderProcessor.process(command); // 비즈니스 트랜잭션 수행
}
Long currentProductId = productIds.get(index);
String lockKey = "lock:product:" + currentProductId;
// 현재 순서의 상품 락 획득 시도 (DistributedLockExecutor에게 위임)
return distributedLockExecutor.execute(
lockKey, Duration.ofSeconds(3), Duration.ofSeconds(5),
() -> executeLocksRecursively(productIds, index + 1, command) // 다음 인덱스 상품 락을 위한 재귀 호출
);
}
재귀 락의 메모리 스택 동작 구조 (LIFO 구조의 완성)
이 재귀 구조는 자바의 메서드 실행 콜 스택(Call Stack) 메커니즘을 타고 자연스럽게 후입선출(LIFO, Last In First Out) 형태로 작동한다.

호출이 깊어질 때마다 락이 차례대로 걸리고, 핵심 비즈니스가 끝나면 스택이 역순으로 팝(Pop)되면서 finally 블록의 언락 로직이 연쇄적으로 작동한다. 가장 마지막에 잡았던 락이 가장 먼저 풀리는 완벽하게 안전한 생명주기가 완성되는 것이다.
5.2 DistributedLockExecutor 추상화와의 우아한 결합
이 복잡한 다중 재귀 락 메커니즘 속에서도 우리가 앞서 지난 설명에서 구축해 둔 락 실행기(DistributedLockExecutor)의 추상화 가치는 빛을 발했다. 재귀 메서드 내부를 보면 직접 Redisson 클라이언트를 제어하지 않고 distributedLockExecutor.execute(...)를 호출하고 있다. 서비스 레이어는 여전히 "어떤 식별자로 락을 정렬해 잡을 것인가"에 대한 정책만 결정할 뿐, 실제 락의 타임아웃 밸류 핸들링, 스레드 소유권 검증, 락 반납 같은 물리적 상세 구현에는 전혀 의존하지 않는다. 코드의 응집도와 격리 수준이 최고 수준으로 유지되는 구조다.
1) 최종 다중 상품 주문 락 파이프라인 전략 요약
데드락을 방지하고 다중 상품의 재고 정합성을 완벽하게 보장하기 위해 정립한 최종 [다중 상품 주문 요청 진입] 락 워크플로우 6단계는 다음과 같다.
- 1단계: 주문서 내의 모든 상품 ID 수집 (`productIds`)
- 2단계: 불필요한 인프라 부하를 막기 위한 중복 제거 (`distinct()`)
- 3단계: 데드락을 원천 차단하기 위한 오름차순 전역 정렬 (`sorted()`)
- 4단계: 스택 메커니즘 기반의 정방향 순차 Lock 획득 (`executeLocksRecursively()`)
- 5단계: 락 엄호 상태에서 안전하게 트랜잭션 실행 및 DB 영속화 (`CreateOrderProcessor`)
- 6단계: 안전장치(`isHeldByCurrentThread`) 기반의 역순(LIFO) 자동 Lock 해제
이 고도화된 정렬 및 재귀 락 전략 덕분에, 우리 프로젝트는 단일 상품 주문을 넘어 아무리 복잡한 다중 장바구니 주문 요청이 동시 다발적으로 밀려들어도 데드락 장애 제로(0%), 초과 판매 제로(0%)의 단단한 무결성 주문 시스템을 완성할 수 있었다.
6. Redis Distributed Lock 적용 전후 비교 테스트
6.1 "개선"은 오직 측정으로만 증명된다
아키텍처 설계와 기술적 전환 과정에서 가장 경계해야 할 태도는 "Redis 분산 락을 도입했으니 동시성 문제가 당연히 해결되었을 것"이라는 막연한 낙관론이다. 수많은 프로젝트가 기술 스택의 변경 자체를 '개선'이라 부르며 넘어가지만, 실제 비즈니스 환경에서 가치를 증명하려면 반드시 정량적인 지표로 이를 측정하고 비교해야 한다. 이번 프로젝트에서는 우리가 고안한 Redis 분산 락 아키텍처가 실제로 비즈니스 요구사항을 만족하는지 검증하기 위해 동일한 통합 테스트 환경(CreateOrderConcurrencyComparisonTest)을 구축했다. 그리고 다음의 두 가지 제어 전략에 완벽히 동일한 강도의 피크 트래픽 부하를 발생시켜 데이터를 수집했다.
- BEFORE: JPA @Version 기반의 낙관적 락(Optimistic Lock) 전략 (createOrderServiceV1)
- AFTER: Redisson 기반 전역 정렬 및 재귀 분산 락(Distributed Lock) 전략 (createOrderService)
1) 지표 측정을 위한 부하 테스트 시나리오
테스트는 실제 한정판 선착순 상품 판매 상황과 유사한 극단적인 경합 상태를 의도적으로 재현했다.
- 초기 가용 재고: 10개 (INITIAL_STOCK = 10)
- 동시 주문 요청: 100개 (REQUEST_COUNT = 100)
- 시뮬레이션 스레드: 32개 멀티스레드 풀 (THREAD_COUNT = 32)
- 주문 조건: 100명의 가상 유저가 동일 상품에 대해 정확히 1개씩 동시에 주문을 생성한다.
올바른 시스템이라면 두 방식 모두 10명 성공, 90명 실패라는 결과와 함께 최종 재고 무결성을 지켜내야 한다. 하지만 이번 측정의 핵심은 성공 횟수가 아니다. "실패한 90명의 사용자가 시스템으로부터 어떤 피드백을 받으며 실패하는가", 즉 실패의 질적 차이를 규명하는 것이 핵심이다.
2) [BEFORE] 낙관적 락(Optimistic Lock) 테스트 지표 분석
먼저 기존 낙관적 락 환경에서 수집된 원시 로그 데이터다.

===== BEFORE Optimistic Lock 동시성 테스트 결과 =====
initialStock = 10
requestCount = 100
successCount = 10
failCount = 90
[최종 DB 재고 상태]
totalQuantity = 10
reservedQuantity = 10
soldQuantity = 0
availableQuantity = 0
[발생한 예외 지표 통계]
ObjectOptimisticLockingFailureException = 84
StaleObjectStateException = 84
StaleStateException = 84
ProductException = 6
지표 해석: 기술적 실패로 전가된 사용자 경험
지표상으로 데이터 무결성은 완벽히 방어되었다. 최종 가용 재고는 정확히 0이 되었고, 단 한 건의 초과 판매(Overselling)도 발생하지 않았다. 그러나 예외 통계를 보면 처참한 수준의 부작용이 드러난다. 실패한 90건 중 우리가 의도했던 비즈니스 예외인 재고 부족(ProductException)은 단 6건에 불과했다. 나머지 84건은 전부 DB 버전 충돌 예외(ObjectOptimisticLockingFailureException)로 채워졌다. 이것은 스레드들이 동시에 가용 재고(availableQuantity = 10)를 확인하고 비즈니스 검증을 통과했음에도, 단지 커밋 시점에 버전이 맞지 않는다는 이유로 시스템 내부 충돌 에러를 맞으며 강제로 튕겨 나갔음을 의미한다. 아직 재고가 8~9개나 남아있던 시점에 진입한 유저들까지 시스템 오류로 주문이 취소되는 최악의 사용자 경험을 유발한 것이다.
3) [AFTER] Redis 분산 락(Distributed Lock) 테스트 지표 분석
동일한 코드 셋에서 외부 분산 락과 트랜잭션 경계 분리(Processor 아키텍처)를 적용한 후 수집된 데이터 지표다.

===== AFTER Redis Distributed Lock 동시성 테스트 결과 =====
initialStock = 10
requestCount = 100
successCount = 10
failCount = 90
[최종 DB 재고 상태]
totalQuantity = 10
reservedQuantity = 10
soldQuantity = 0
availableQuantity = 0
[발생한 예외 지표 통계]
ProductException = 90
지표 해석: 100% 비즈니스 실패로의 수렴
분산 락 적용 후의 결과 역시 10건 성공, 90건 실패로 정합성을 깔끔하게 유지했다. 테스트 코드의 단언문인 `containsOptimisticLockException()`은 false를 기록했다. 시스템 내부 충돌을 뜻하는 `ObjectOptimisticLockingFailureException`를 비롯한 모든 데이터베이스 단의 락 에러가 0건으로 완전 소멸한 것이다.
그 자리를 채운 것은 오직 하나, ProductException (90건)뿐이었다. 락을 통해 진입 순서가 정렬되면서, 선착순 10명이 재고를 순차적으로 완벽히 소진시켰고, 11번째 스레드부터는 명확하게 "남은 재고가 부족합니다"라는 비즈니스 규칙에 의해 정상적으로 거절 처리되었다.
6.2 두 제어 전략의 핵심 패러다임 변화
두 테스트 지표가 보여주는 아키텍처적 차이는 다음과 같이 요약할 수 있다.
1) 낙관적 락: 충돌 후 사후 감지 (Post-Conflict Detection)
- 100명 진입 ──> 100명 동시에 DB 재고 수정 시도 ──> 84명 버전 충돌 유발 (대량 예외 및 롤백 비용 발생)
비즈니스가 인프라의 기술적 한계에 의존한다.
시스템이 동시 수정을 감당하지 못해 에러를 뿜어내고, 사용자는 매진이 아닌 '서버 오류'를 경험한다.
2) Redis 분산 락: 충돌 전 원천 예방 (Pre-Conflict Prevention)
- 100명 진입 ──> Redis 분산 락이 1열 종대로 순차 정렬 ──> 10명 성공 ──> 90명 "재고 부족" 비즈니스 응답
인프라 레이어에서 트래픽을 선제적으로 제어하여 DB로 향하는 충돌 자체를 완전히 제거한다.
기술적 한계가 비즈니스 규칙 안으로 우아하게 흡수된다.
3) 최종 결론 및 분산 락의 한계 검토
테스트 결과를 종합하면 다음과 같다.
| 항목 | Optimistic Lock | Redis Distributed Lock |
| 초과 판매 방지 및 정합성 | ⭕ 보장 | ⭕ 보장 |
| Version 충돌 발생 | ❌ 대량 발생 (84건) | ⭕ 완전 제거 (0건) |
| DB 경합 부하 | ❌ 매우 높음 (수정 충돌 및 롤백) | ⭕ 낮음 (락 획득 스레드만 접근) |
| 사용자 경험 (UX) | ❌ 원인 불명의 주문 실패 에러 | ⭕ "재고 부족" 정상 안내 |
| 선착순 처리 적합성 | ❌ 부적합 (동시 수정 실패) | ⭕ 적합 (진입 순서 직렬화) |
결과적으로 Redis Distributed Lock은 낙관적 락의 한계였던 시스템 충돌을 제거하고, 기술적 예외를 정상적인 비즈니스 실패(재고 부족 안내)로 전환하는 데 성공했다. 하지만, 여전히 해결되지 않은 분산 락의 명확한 한계가 존재한다. 이 구조가 대규모 트래픽을 처리하는 완벽한 정답은 아니다. 분산 락 기반의 동기식(Synchronous) 처리 구조는 여전히 다음과 같은 치명적인 한계를 내포하고 있다.
- 동기식 블로킹(Blocking)으로 인한 스레드 고갈
- 아무리 Redis가 빠르게 락을 중재하더라도, 사용자의 요청은 락을 얻을 때까지 최대 3초간 애플리케이션 스레드를 붙잡고 대기(Lock Wait)한다. 피크 트래픽이 순간적으로 수만 건 이상 몰리면 WAS(Tomcat)의 스레드 풀이 순식간에 고갈되어 시스템 전체가 먹통이 되는 '스레드 잠김 현상'을 피할 수 없다.
- 트래픽 스파이크(Spike)에 취약한 구조
- 락을 획득한 스레드들은 순차적으로 DB에 직접 접근하여 쓰기 연산을 수행한다. 트래픽이 폭발하는 시점에는 대기 큐에서 풀려난 요청들이 연달아 DB 커넥션을 점유하므로, RDB의 CPU 사용량이 치솟고 전체적인 처리량(Throughput)이 급격히 저하된다.
- 강한 결합도와 성능 제약
- 주문 생성 프로세스 안에 [락 획득 $\rightarrow$ DB 트랜잭션 $\rightarrow$ 주문 영속화]가 하나로 묶여 있어, 전체 API의 응답 시간(Latency)이 길어진다. 사용자는 무거운 DB 작업과 인프라 제어가 끝날 때까지 화면을 붙잡고 기다려야만 한다.
4) 다음 단계를 위한 조사: 비동기 메시지 큐(RabbitMQ / Kafka) 도입의 필요성
결국 분산 락은 "동기식 요청-응답 아키텍처 내에서 정합성을 안전하게 지키는 최선의 방어책"일 뿐, 밀려드는 트래픽의 압력을 흡수하는 근본적인 해결책이 될 수 없다. 진정으로 대규모 트래픽 환경에서도 무너지지 않는 선착순 시스템을 구축하려면, 요청을 받는 서빙 레이어와 실제 재고를 차감하는 적재 레이어를 물리적으로 분리하는 "비동기 이벤트 기반 아키텍처(Asynchronous Event-Driven Architecture)"로의 패러다임 전환이 필수적이다. 우리가 마주한 다음 과제는 분산 락의 대기 큐를 애플리케이션 내부 스레드가 아닌, 대규모 메시지 수용력이 검증된 메시지 브로커(RabbitMQ 또는 Kafka)로 이관하는 것이다. 밀려드는 수만 건의 주문 요청을 메시지 큐에 순서대로 쌓아두고(Throttling), 유저에게는 초고속으로 "주문이 접수되었습니다"라는 응답을 준 뒤, 백그라운드 워커가 자원 상황에 맞춰 안전하게 재고를 차감하는 구조다.