
미리 살펴보는 문제 상황
- 주문 조건 조회 API와 회원별 주문 통계 조회 API의 평균 응답 시간이 3초 이상 발생
- 로그 분석 및
EXPLAIN결과, 다음과 같은 병목 지점을 확인
1. Full Scan 발생
복합 조건 검색(날짜, 상태, 최소 금액 등) 시 적절한 인덱스가 없어 v1_orders에서 테이블/인덱스 풀 스캔이 발생
2.실시간 GROUP BY 통계 집계
회원별 주문 통계 조회 시 v1_orders + v1_members를 실시간으로 GROUP BY 하면서
임시 테이블 생성 및 대량 집계 연산으로 응답 시간이 길어짐
3. N+1 문제로 인한 불필요한 JOIN/조회
복합 주문 검색 결과(페이지당 20건)에 대해, 각 주문별로 order_items를 추가 조회
-> DTO 변환 시 order.getOrderItems().size() 호출로 주문 아이템 조회 쿼리 20번 추가 발생
해결방법
(1) 복합 인덱스 적용
- 문제: 주문 검색 시 상태 + 금액 + 날짜 조건으로 조회할 때 인덱스가 맞지 않아 매번 풀 스캔 + 정렬 비용 발생
- 조치: 자주 사용하는 조건·정렬 기준을 묶은 복합 인덱스 추가
- 효과: 주문 검색 쿼리 실행 시간 약 3초 이상 -> 20ms로 단축, DB 부하 감소
(2) 통계 집계 테이블 + 배치 처리
- 문제: 회원별 주문 통계를 조회할 때마다 실시간 GROUP BY 로 대량 주문 데이터를 매번 집계 → 응답 2~3초 소요
- 조치:
v2_order_stats집계 테이블을 도입해 회원별 주문 수, 총액, 평균 금액, 마지막 주문 일자를
배치(@Scheduled)로 3분마다 미리 계산 - 효과: 통계 API는 집계 테이블 덕분에 단순 SELECT 만 수행
회원별 통계 응답 시간 약 3초 이상 → 81ms 내외로 단축
(3) 반정규화로 N+1 문제 해소
- 문제: 주문 목록에 “아이템 개수”만 필요하지만, 각 주문마다
order_items전체를 로딩해서 개수를 세는 방식
-> 페이지당 20건이면 20번 추가 조회(N+1) - 조치: 주문별 아이템 개수를 나타내는
total_items컬럼을v2_orders테이블에 반정규화
주문 목록 조회 시order_items를 따로 조회하지 않고total_items만 사용 - 효과: 주문 조회 시 쿼리 1회로 아이템 개수까지 함께 제공, N+1 쿼리 제거로 불필요한 I/O와 응답 지연 감소
개선 전후 성과
- 주문 검색 API: 평균 3초 이상 → 20ms 내외
- 회원별 통계 조회: 평균 3초 이상 → 81ms 이하
- DB 서버 부하: 인덱스 미스/풀 스캔 감소로 CPU 사용률 안정화
- N+1 쿼리 수: “아이템 개수” 조회 시 불필요한 쿼리 대부분 제거
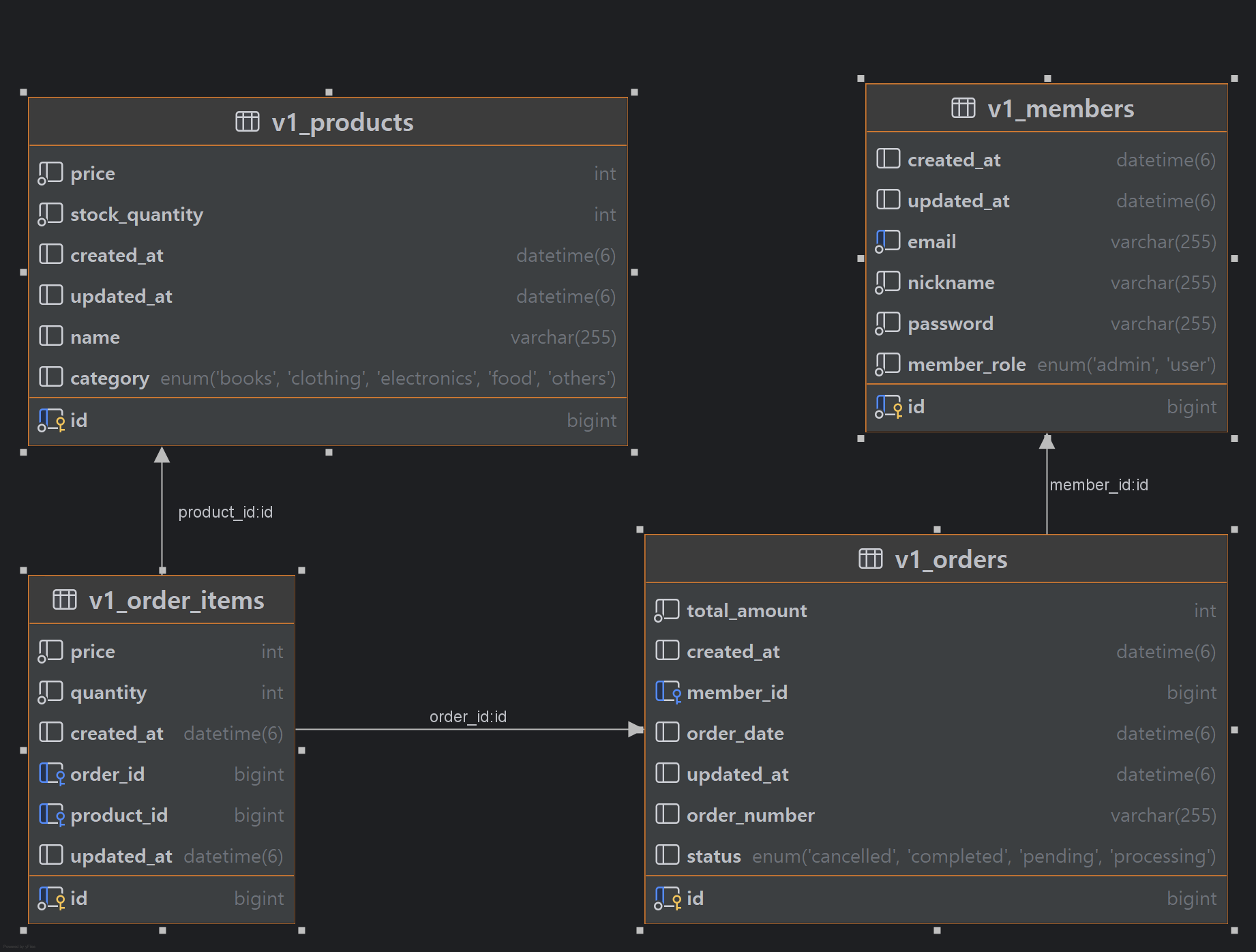
1. 도메인 구조 소개
테이블과 도메인 구조
시작하기 전, 프로젝트의 문제 발생과 관련된 도메인 구조에 대해서 먼저 설명을 드리겠습니다.
테이블과 도메인 구조는 다음과 같습니다.
v1_members(회원)
- 회원 정보(이메일, 닉네임, 비밀번호)
- 회원 권한(ADMIN, USER)
- 시간 정보(생성, 수정일자)
v1_products(상품)
- 상품 정보(이름, 가격, 재고수량)
- 카테고리 분류(ELECTRONICS, CLOTHING, BOOKS, FOOD, OTHERS)
- 재고 관리(stock_quantity)
v1_orders(주문)
- 주문 정보(주문번호, 주문일자, 총액)
- 주문 상태 관리(PENDING, PROCESSING, COMPLETED, CANCELLED)
v1_order_items(주문상품)
- 주문과 상품의 다대다 관계를 풀어내기 위한 테이블
- 주문 시점의 가격과 수량 스냅샷
- 주문 상세 내역 관리
각 테이블마다 임의로 넣은 더미 데이터 수는 다음과 같습니다.
- 주문 50만 개
- 회원 100만 개
- 주문 상품 150만 개
- 상품 1만개

네이버 혹은 쿠팡과 같은 커머스 서비스라고 생각하시면 됩니다.
- 쿠팡에서 상품을 보게 된다면
v1_products - 구매까지 이어진다면
v1_orders가 생성 orders내부에 있는 상품의 각 아이템들은v1_order_items로 저장
되는 흐름입니다.
핵심 엔드포인트
OrderController안에 두 개의 중요한 검색 엔드포인트가 있습니다.
- 복합 조건 주문 검색 API(/complex-search)
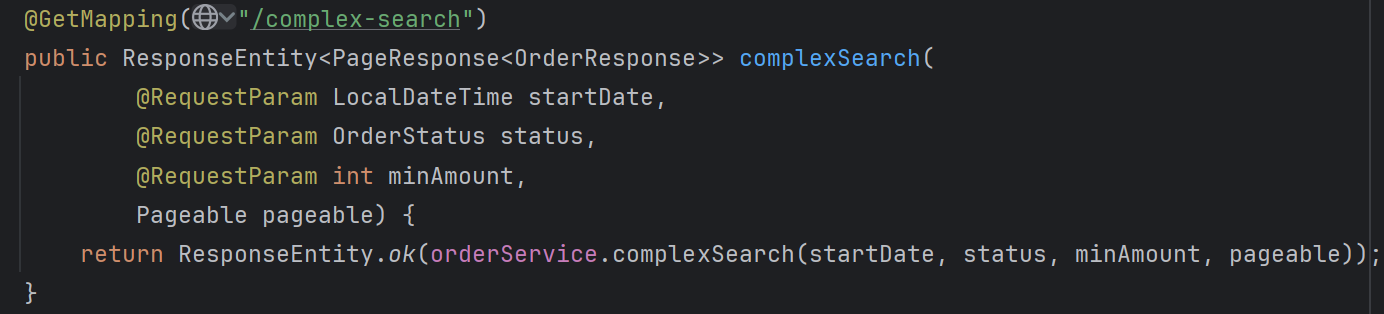
요청 예시: GET /api/v1/orders/complex-search?startDate=2024-01-01T00:00:00&status=COMPLETED&minAmount=100000
- 기능: 여러 조건을 조합한 주문 검색
- 파라미터
startDate: 특정 날짜 이후 주문status: 주문 상태minAmount: 최소 주문 금액pageable: 페이징 정보
- 사용 사례
- "2024년 2월 이후의 10만원 이상 결제 완료된 주문 검색"
- "특정 기간의 취소된 고액 주문 조회"
2. 회원별 주문 통계 API(/stats)

요청 예시: GET /api/v1/orders/stats?minAmount=50000&page=0&size=20
- 기능: 회원별 주문 통계 조회
- 파라미터
minAmount: 최소 주문 금액 기준(선택)pageable: 페이징 정보
- 통계 정보
- 총 주문 건수
- 총 주문 금액
- 평균 주문 금액
- 마지막 주문일자
- 사용 사례
- "15만원 이상 구매 회원 통계"
- VIP 고객 대상 구매 패턴 분석"
2. 문제 상황
상품과 주문 API 호출 테스트를 하면서 다른 API에 비해 매우 오랜 시간이 걸리는 것을 확인했습니다.
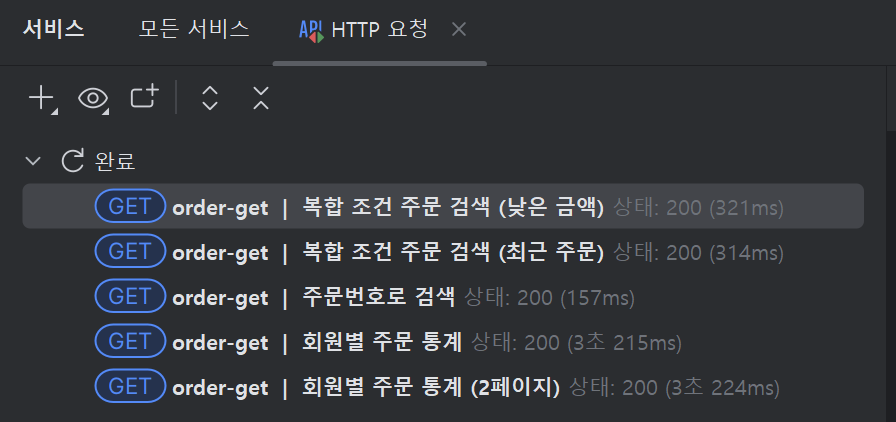
- 복합 조건 주문 검색 API(/complex-search)
- 평균 응답 속도 300ms 이상 발생
- 특정 환경에서는 1초 이상 소요될 가능성
- 회원별 주문 통계 API(/stats)
- 3초 이상의 응답 속도로, 사용자 경험에 큰 문제가 될 가능성이 높음
나머지 API 응답 속도는 31ms ~ 160ms 사이의 응답 속도로 위의 두 개 API보다 빠른 응답 속도를 확인했습니다.
정리하자면 다른 API 응답 속도 확인과 함께 특정 두 개의 느린 API에서 문제가 있다는 것을 파악했습니다.
3. 문제 파악과 해결: 복합 조건 주문 검색 API
### 복합 조건 주문 검색 (낮은 금액)
GET /api/v1/orders/complex-search?startDate=2023-01-01T00:00:00&status=COMPLETED&minAmount=500
Content-Type: application/json가장 먼저 복합 조건 주문 검색 API를 실행하면 어떤 쿼리가 실행되는지를 파악했습니다.
위와 같이 "2023년 1월 1일 이후의 500원 이상 결제 완료된 주문 검색"을 수행합니다.
수행되는 쿼리는 다음과 같은 쿼리가 콘솔창에 출력되는 것을 볼 수 있습니다.

해당 쿼리를 그대로 복사하고 MySQL WorkBench에서 쿼리 플랜을 실행하여 실행 계획을 확인하고, 문제점이 무엇인지 파악했습니다.
desc
select
o1_0.id,
o1_0.created_at,
o1_0.member_id,
o1_0.order_date,
o1_0.order_number,
o1_0.status,
o1_0.total_amount,
o1_0.updated_at
from
v1_orders o1_0
where
o1_0.order_date>='2023-01-01T00:00:00'
and o1_0.status='COMPLETED'
and o1_0.total_amount>=50000
order by
o1_0.order_date desc
limit
100;
문제 파악
type - ALL: 50 만 건의 전체 테이블 스캔 발생possible_keys - NULL: 조건절에 사용할 인덱스 없음filtered - 2.78: 전체 데이터 중 2.78%만 실제 필요한 데이터Extra - Using Where;fileSort: ORDER BY를 위한 추가 정렬 작업이 필요한 상태
쿼리 플랜의 실행 계획이 위처럼 조회된 이유는 다음과 같습니다.
- 조건 컬럼(
order_date, status, amount)에 맞는 복합 인덱스 부재 - 정렬 조건(
order_date DESC)에 맞는 인덱스가 부재
정렬을 위한 인덱스가 부재하기 때문에 전체 데이터를 다 보고 메모리 안에서 정렬 작업을 수행하기 때문에 매우 느리다는 것을 의미합니다. 항상 데이터를 조회할 때 마다 정렬을 해야하기 때문이에요.
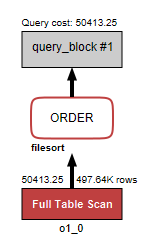
EXPLAIN 시각화로 보면 쿼리 흐름과 빨간색의 경고와 함께 아래 사실을 알 수 있습니다.
- Full Table Scan 발생
o1_0테이블을 인덱스 없이 전체 스캔하고 있어요. rows ≈ 497.64K- 조건에 해당 컬럼에 적절한 인덱스가 없거나 선택도가 낮아 인덱스를 타지 못하는 상황입니다.
- ORDER BY가 인덱스를 못 타서 filesort
- 정렬 단계가 filesort(메모리/디스크 임시 영역 정렬)로 처리됩니다.
- 즉, ORDER BY 컬럼에 대한 적절한(선행 컬럼 포함 순서까지 맞는) 인덱스가 없음을 의미합니다.
- 비용이 큰 쿼리
- cost ≈ 50,413: MySQL의 추정 비용이 높은 편 → 전체 스캔 + 대량 정렬로 리소스/시간 많이 발생됩니다.
문제 해결
실행 계획으로 인덱스 부재로 인한 문제라는 사실을 파악했습니다.
복합 인덱스를 추가하고 쿼리를 최적화합니다.

그리고 다시 쿼리 플랜을 살펴봅니다.

개선된 점
type - ALL -> range: 전체 테이블 스캔에서 인덱스 범위 스캔으로 개선order_date범위 조건을 인덱스로 조회Using filesort제거- 정렬 조건 ORDER BY가 인덱스를 통해 처리
- 추가적인 정렬 작업이 없음

1. Index Range Scan 발생o1_0 테이블을 더이상 전체 스캔하지 않고, idx_order_date_status_amount 인덱스 연속 구간만 스캔합니다. (rows ≈ 248.82K)
2. filesort 제거
ORDER BY 순서와 동일한 인덱스 정렬 순서를 만족합니다. 그래서 filesort 없이 인덱스 순서로 반환합니다.
복합 인덱스 추가해서 추정된 rows가 ~248.8K로, 이전 Full Table Scan(약 497.6K)보다 절반가량 줄었습니다.
복합 인덱스의 컬럼명 순서 order_date desc, status, total_amount와 WHERE 절의 순서를 동일하게 작성해서 idx_order_date_status_amount 인덱스가 적용되어, 필요한 구간만 빠르게 스캔할 수 있었습니다. 그리고 인덱스의 첫 번째 컬럼은 order_date desc 기준으로 정렬된 상태이므로, 별도의 filesort 과정이 사라졌습니다.
status, total_amount 조건 또한 인덱스 안에서 처리 가능하므로, 불필요한 레코드 접근을 대폭 줄였습니다.
쿼리 실행 과정이 간소화되고, 대량 데이터 정렬 작업까지 해소되어 응답 속도가 크게 향상될 수 있었습니다.
보고 및 성과
최초 문제 상황
select *
from v1_orders o1_0 -- 주문 테이블에서
where o1_0.order_date>='2023-01-01T00:00:00' -- 23년 01월 이후만
and o1_0.status='COMPLETED' -- 그리고 완료된 주문만
and o1_0.total_amount>=50000 -- 그리고 5만원 이상만
order by o1_0.order_date desc -- 주문 최신날짜 순으로 (주문 날짜 기준)
limit 100; -- 100개만 조회
실행 계획 결과
type - ALL: 전체 테이블 스캔rows - 497640: 50만 건 스캔Extra - Using Where;fileSort: 정렬을 위한 추가 작업
개선된 실행 방식
type - range: 인덱스 범위 스캔key:idx_order_date_status_amountUsing index condition: 인덱스로 조건 처리
성능 개선 효과
- 전체 테이블 스캔 -> 인덱스 범위 스캔
- 추가적인 정렬 작업 제거
- 쿼리 실행 시간: 3초 이상 -> 20ms
4. 문제 파악과 해결: 회원별 주문 통계 API
문제 파악
### 회원별 주문 통계
GET /api/v1/orders/stats?minAmount=50000&page=0&size=20
Content-Type: application/json회원별 주문 통계 API를 먼저 실행하여 어떤 쿼리가 실행되는지를 파악합니다.
"회원별 최소 주문 금액이 50,000원인 주문 통계 20건 조회"를 수행합니다.
다음과 같은 두 번의 쿼리가 콘솔창에 출력되는 것을 볼 수 있습니다.
해당 쿼리를 그대로 복사하고 MySQL WorkBench에서 쿼리 플랜을 실행하여 실행 계획을 확인하고, 문제점이 무엇인지 파악했습니다.
desc
select
m.email as memberEmail,
count(*) as totalOrders,
sum(o.total_amount) as totalAmount,
avg(o.total_amount) as averageAmount
from
v1_orders as o
join
v1_members as m
on o.member_id = m.id
group by
m.email
having
sum(o.total_amount) >= 5000
limit
100 ;
테이블 m의 접근 방식
type - index: 인덱스 풀 스캔이 발생
테이블 전체를 대상으로 데이터 페이지 대신 인덱스 트리를 이용해서 모든 레코드를 스캔합니다.rows - 990900으로 인덱스에 약 99만 개의 레코드가 존재하고, 그걸 모두 다 훑어보겠다는 의미possible_keys: PRIMARY, UK5kfu3alv52x2vasqmbspjoooc 두 개의 인덱스 후보id: AUTO_INCREMENT,email: unique=true으로 인하여 인덱스가 존재하기 때문에 인덱스 두 개가 후보에 해당key - UK5kfu3alv52x2vasqmbspjoooc:email컬럼의 UNIQUE 인덱스를 사용하는 것으로 결정
UK5k... 같은 이름인 이유는 JPA/Hibernate가 @Column(unique = ture)같은 설정을 보고 자동으로 만든 UNIQUE 인덱스 이름입니다. 그 인덱스의 컬럼이 바로 m.email이고, MySQL은 이번 쿼리에서 UK5k... 이 인덱스를 사용(key) 하기로 결정했습니다.
핵심 포인트 Extra - Using index: 커버링 인덱스(Covering index)로 처리 가능한 경우
Using index의 의미는 m 테이블에 대해 SELECT, GROUP BY, HAVING에 필요한 컬럼을 전부 인덱스에서만 읽을 수 있다는 것을 의미합니다. 그래서 실제 테이블 데이터 페이지로 내려가지 않습니다. 집계 쿼리가 m에서 필요한 것은 다음과 같습니다.
- SELECT:
m.email - GROUP BY:
m.email - HAVING:
SUM(o.total_amount)
이 세 가지 조건만 사용하고, m의 다른 컬럼은 필요 없습니다. JOIN에서 내부적으로 m.id도 필요하지만 InnoDB의 보조 인덱스는 리프 노드에 PK(m.id)를 같이 갖고 있습니다. 따라서 email 인덱스 한 줄 안에 사실상 (email, id) 정보를 모두 갖고 있습니다.
emailUNIQUE 인덱스를 위에서부터 아래까지 쭉 읽으면서,- 인덱스에 같이 붙어있는
id값으로o.member_id = m.id조인을 수행하고, m테이블은 단 한 번도 "클러스터드 인덱스(실제 데이터 페이지)"를 보러 가지 않아도 됩니다.
- 인덱스를 풀 스캔:
type = index,rows ≈ 990900 m.email은 인덱스만 보고 해결:Extra = Using index- 테이블 데이터(클러스터드 인덱스)로 랜덤 접근이 안 나감
테이블 o의 접근 방식
type - ref: 조인 시 자주 나타나는 접근 방법
인덱스를 사용하여 하나 또는 그 이상의 행에 접근하는 방식을 의미합니다. "데이터베이스가 인덱스를 통해 효율적으로 특정 조건에 맞는 행들을 찾아내고 있다"는 것을 나타내는 지표로, 일반적으로 FK 인덱스를 이용해 키 값으로 매칭해요.possible_keys - FKed8kuvmg3n0u042gg8vf6de0i:o.member_id에 설정된 외래키 인덱스(자동 생성된 FK 인덱스)key - FKed8kuvmg3n0u042gg8vf6de0i: 실제 사용 인덱스 역시 FK 인덱스ref - arctic.m.id: 를 기준으로 매칭rows - 1: 각m.id마다o에서 매칭되는 레코드가 1건 정도라고 추정
“한 명의 회원당 주문 1건 정도 나올 거라고 예상한다” 정도의 통계 정보입니다.
따라서 조인 순서는 다음과 같습니다.
m의emailUNIQUE 인덱스를 풀 스캔(UK5k...)하고,- 각 멤버에 대해
o.member_id인덱스를 통해 필요한 관련 주문 레코드들을 찾고, - 그걸 가지고
SUM(o.total_amount),AVG(o.total_amount)를 계산한 뒤, GROUP BY m.email,HAVING sum >= 5000을 적용합니다.
쿼리 시각화
MySQL WorkBench 시각화를 보면 nested loop는 o1_0와 m1_0 사이에서 수행되고 있습니다.
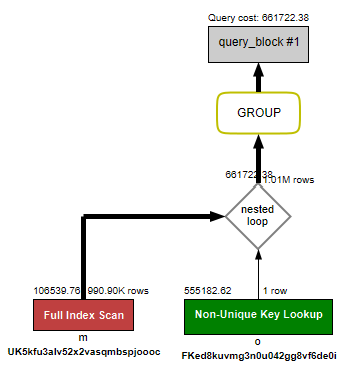
nested loop 는 말 그대로 반복 수행입니다.
for each row in m (인덱스 풀 스캔):
해당 m.id 로 o.member_id 인덱스에서 주문 찾기
(찾은 o 행과 m 행을 붙여서 한 row 로 만들어 위로 올림)FOR EACH row in members (외부 테이블) // 외부 루프 -- 드라이빙
FOR EACH matching row in orders // 내부 루프
IF join-condition matches THEN -- 드리븐
RETURN combined rowMySQL에서 두 테이블을 JOIN하면 가장 기본적인 동작 방식은 Nested Loop Join입니다.
그리고 드라이빙 테이블(Driving Table), 드리븐 테이블(Driven Table)의 개념에 대해 이해해고 있어야 합니다.
드라이빙 테이블과 드리븐 테이블 개념
드라이빙 테이블은 SQL JOIN을 수행할 때 가장 먼저 접근하여 접근 경로를 주도하는 테이블을 의미하며, 드리븐 테이블은 나중에 접근하는 테이블을 말합니다. 드라이빙 테이블은 OUTER TABLE로, 드리븐 테이블은 INNER TABLE로도 불리며, 어떤 테이블이 드라이빙 테이블이 될지는 INDEX 존재 여부나 FROM 절의 순서 등에 영향을 받습니다
- 드라이빙 테이블(Driving table)
- 조인을 시작할 때 가장 먼저 읽는 테이블
- 바깥 루프(outer loop)에 오는 테이블
- 드리븐 테이블(Driven table)
- 드라이빙 테이블에서 나온 행을 기준으로 그 다음에 접근하는 테이블
- 안쪽 루프(inner loop)에 오는 테이블
| 구분 | 드라이빙 테이블 (Driving Table) | 드리븐 테이블 (Driven Table) |
| 정의 | JOIN 시 가장 먼저 접근하여 접근 경로를 주도하는 테이블 |
JOIN 시 드라이빙 테이블에 이어 나중에 접근하는 테이블 |
| 다른 이름 | OUTER TABLE |
INNER TABLE |
| 영향 | 쿼리 성능에 큰 영향을 미치므로, 튜닝 시 가장 중요하게 고려되는 대상 |
- |
그래서 실행 계획에서 누가 누구?

EXPLAIN 결과에서 table 컬럼에 나열된 순서가, MySQL의 Nested Loop Join에서 outer loop (드라이빙 테이블) → inner loop (드리븐 테이블) 순서를 보여줍니다. 따라서 EXPLAIN 결과에서 m 테이블이 먼저 나오고, o 테이블이 두 번째로 나왔다면, m이 드라이빙 테이블입니다!
쿼리 도식화의 순서를 정리하면 다음과 같습니다.
- Full Index Scan(m)
- Nested Loop
- Non-Unique Key Lookup(o)
- GROUP
- 드라이빙 테이블 =
m(v1_members)- email 인덱스를 Full Index Scan 하면서 한 회원씩 읽어 올라갑니다.
- 드리븐 테이블 =
o(v1_orders)- 각
m.id에 대해o.member_id인덱스를 이용해 lookup 합니다. - 따라서
o는 "m에 의해 끌려다니는" 테이블이라서 Driven 입니다.
- 각
for each member in m (email 인덱스 풀스캔):
for each order in o
where order.member_id = member.id:
-> GROUP BY member.email, SUM(order.total_amount) ...“멤버 테이블을 먼저 한 바퀴 돌리고, 각 멤버마다 주문 테이블을 인덱스로 찾아 들어간다” 라고 이해하면 됩니다.
옵티마이저가 정하는 드라이빙 테이블
- 좋은 인덱스(UNIQUE email)로 순차 스캔해서(
type = index,Using index) 테이블 랜덤 I/O 안 하고 인덱스만 쭉 읽도록 합니다. - 조인 조건이
o.member_id = m.id인데,o.member_id에도 인덱스가 있습니다.
그래서 “m 한 줄 <-> o 인덱스 lookup” 패턴의 nested loop 가 깔끔하게 조회됩니다. - GROUP BY 기준이
m.email이라m을 먼저 읽어도 논리적으로 문제 없습니다.
물론, 쿼리를 바꿔서 먼저 orders 를 집계한 뒤 members 와 조인하게 만들면 그때는 옵티마이저에 의해 o 가 드라이빙 테이블이 될 수 있어요.
빨간색 박스로 도식화되는 이유
DB 입장에서 Full Scan(테이블/인덱스)은 항상 이렇게 취급됩니다. “필요한 row만 골라서 보는 게 아니라 일단 전부 다 훑어야 하는 연산” 이기 때문에 비용이 매우 큽니다. 그나마 Table Full Scan 보다는 Index Full Scan이 낫지만, 그래도 O(N) 으로 전부 읽어야 합니다. 그러나 "빨간색 = 반드시 나쁜 플랜"은 아닙니다.
이번 쿼리에서는 어쩔 수 없이 GROUP BY m.email을 해야 해서 애초에 모든 멤버를 한 번씩은 봐야되는 쿼리입니다. 그래서 테이블 전체 스캔 보다는 email 인덱스만 전부 읽는 것이 더 비용이 저렴하기 때문에 Full Index Scan + Using Index를 옵티마이저가 선택했습니다. 상대적으로 작업이 무거운 것은 사실이지만, 쿼리의 목적상 그나마 최선라고 볼 수 있습니다.
Non-Unique Key Lookup(o) 데이터베이스가 중복을 허용하는 인덱스를 사용해 데이터를 찾되, 필요한 모든 컬럼 정보를 얻기 위해 추가적인 테이블 검색을 수행해야 하는 상황을 의미합니다.
for each m.id:
o.member_id 인덱스에서 필요한 row만 찾아오기 (ref 접근)각 lookup 자체는 인덱스를 타고 소수의 row만 읽는 작업이라 단일 연산 단위로 보면 낮은 비용니다. 그래서 MySQL Workbench는 이런 인덱스 lookup 계열을 보통 초록색/노란색으로 칠해서 “비교적 효율적인 접근” 으로 보여주고 있습니다. 물론, nested loop 전체로 보면 이 lookup 이 수십만 번 반복되니까 총 cost 는 만만찮지만, 각 노드의 색은 그 방식 자체의 효율성 + 예상 row 수 조합으로 칠해주는 셈입니다. 예를 들어,
m에서 10 건만 읽는다면, 각 건마다o를type: ref로 조회(합쳐서 10번) -> 전체로 보면 부담이 크지 않다!m에서 99 만 건을 읽는다면, 각 건마다o를 조회(합쳐서 약 99만 번) ->ref라 해도 누적 비용이 상당히 크다!
지금까지 파악한 문제 내용을 요약
m테이블을emailUNIQUE 인덱스로 Full Index Scanm이 드라이빙 테이블이고,email인덱스를 outer loop 에서 처음부터 끝까지 스캔함
- 각
m레코드마다m.id로v1_orders를 인덱스 lookup (type = ref)o.member_id에 걸린FKed8kuvm...인덱스를 사용해서 매칭되는 주문들을 찾음- 이 두 단계가 합쳐져서 Nested Loop Join 이 발생하고,
이 과정에서 내부적으로 만들어지는 “중간 조인 결과”가 대략 3 백만 행 정도 생성 - 조인 결과 예상 row 수 ≈ 980,000 (회원 수 추정) × 3 (회원당 주문 수 추정)
≈ 2,940,000 → 대략 3.0M(3 백만 행)
- 조인 결과에 대해
GROUP BY m.email수행하면서 집계 계산COUNT(*),SUM(o.total_amount),AVG(o.total_amount)를m.email그룹별로 계산
- 집계 결과에
HAVING SUM(o.total_amount) >= 5000필터 적용- 그룹별 합계가 5000 이상인 email 그룹만 남김
- 그 중에서 LIMIT 100 건만 최종 결과로 반환
현재 상황에서 성능 최적화 방향 고민
1. Full Index Scan 쿼리 비용의 부담
Full Table Scan 보다 Full Index Scan이 더 좋지만,
현재 WHERE 절이 없기 때문에 MySQL 옵티마이저는 약 99 만 건의 거의 모든 레코드를 검색해야 합니다.
2. 커버링 인덱스 사용
Extra - Using Index으로,
테이블 데이터까지는 접근하지 않고 인덱스 스캔만으로 m.email을 얻는 점은 성능상 유리합니다.
3. Nested Loop Join 특성
- 외부 루프(=
m에서 99 만 건)에 대해 내부 루프(o검색 )를 반복하는 구조입니다. - 내부 루프가
ref타입(인덱스 동등 조건)을 사용하므로,
각 outer row마다 인덱스를 통해 비교적 적은 비용(로그 시간 + 적은 row 수)으로 inner 데이터를 찾을 수 있습니다. member_id인덱스가 없으면 →o에 대해 매번 풀 스캔해야 해서 재앙이고, 인덱스가 있어도,
한m.id당 매칭되는orow 가 엄청 많다면 → 지금처럼 inner loop 비용이 커져서 전체 비용도 확 튀어요.
JOIN을 사용하면 Nested Loop가 기본적으로 발생하는 조인 및 집계 방식입니다.
하지만 현재 상황과 유사한 치명적인 문제점이 다음과 같이 존재합니다.
- 대량의 데이터가 있고
- 반복적으로 실시간 집계가 필요한 경우
Nested Loop는 성능 저하로 이어지게 됩니다.
만약 미리 계산(사전 계산) 방식을 도입하면, 이러한 문제를 대폭 줄일 수 있습니다.
- 중요한 통계를 배치로 계산 후 별도 테이블에 보관
- 조회 시에는 빠른 SELECT 즉시 응답
결과적으로, 대규모 트래픽이 발생하거나 데이터 양이 많은 환경에서 실시간성 혹은 성능 사이에서 균형을 찾는 것이 상당히 중요하고, 사전 계산(집계 테이블) 기법이 그 해답 중 한 가지입니다. 오늘 하루 매출 통계를 확인하는 관리자 대시보드의 경우, 1~2분 정도 늦게 반영되더라도 큰 문제가 없습니다. 덕분에 주문이 들어올 때마다 매번 계산하는 방식보다 훨씬 빠르게 통계 데이터를 조회할 수 있고, 데이터베이스의 부담을 줄일 수 있습니다.
문제 해결
통계 혹은 집계 테이블을 생성합니다.
예를 들어 회원별 주문 통계를 매번 실시간으로 계산하는 대신, 3분마다 한 번씩 백그라운드에서 통계를 계산하여 별도의 테이블에 저장하는 방식입니다. 덕분에 미리 계산된 결과만 조회하면 되므로, 복잡한 조인이나 집계 연산이 불필요하고, 응답 속도도 2~3초 이상에서 0.1초 이하로 크게 개선될 수 있습니다.
그러나 데이터가 실시간성이 아니라는 점이 가장 큰 단점입니다. 하지만 대부분의 통계성 데이터는 수 분 정도의 지연에 큰 문제는 없기 때문에 관리자 대시보드 혹은 일일 매출 현황 같은 용도로 충분히 수용 가능한 수준으로 판단됩니다. 또한 DB 서버의 부하도 크게 줄여주는 덕분에 피크 시간대에 발생하는 DB 부하를 분산시킬 수 있다는 장점이 있습니다.
통계 엔티티 작성
OrderStatsV2 엔티티는 회원별 주문 통계 스냅샷을 저장하는 테이블입니다.
v1_orders 테이블을 member_id로 GROUP BY 해서
- 각 회원의 주문 수(orderCount),
- 총 금액(totalAmount),
- 평균 금액(avgAmount),
- 마지막 주문 일시(lastOrderDate)
여러 통계 데이터를 계산한 뒤 v2_order_stats 테이블에 적재합니다.member_id는 통계의 PK이며, 한 회원당 한 row만 가집니다.
@Entity
@Table(name = "v2_order_stats")
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class OrderStatsV2 {
@Id
private Long memberId;
private String email;
private int orderCount;
private long totalAmount;
private double avgAmount;
private LocalDateTime lastOrderDate;
private LocalDateTime updatedAt;
@PrePersist
@PreUpdate
public void updateTimestamp() {
this.updatedAt = LocalDateTime.now();
}
}
주문 통계 스냅샷 테이블(v2_order_stats)
OrderStatsV2 엔티티는 회원별 주문 통계를 스냅샷 형태로 저장하는 테이블입니다.
기존 주문 테이블인 v1_orders를 member_id 기준으로 집계하여, 다음 정보를 한 행에 모아 둡니다.
member_id: 통계를 대표하는 회원 ID (PK)email: 회원 이메일order_count: 해당 회원의 총 주문 수total_amount: 총 주문 금액 합계avg_amount: 평균 주문 금액last_order_date: 마지막 주문 일자updated_at: 통계가 마지막으로 갱신된 시각
즉, v1_orders에서 매번 GROUP BY member_id를 수행하지 않고, 미리 계산해 둔 결과를 v2_order_stats에 저장해 두었다가 API에서 바로 조회하는 구조입니다. 그 덕분에 조회 시에는 가벼운 단건/다건 SELECT만 수행하면 되고, 무거운 JOIN + GROUP BY 연산은 배치로 따로 분리됩니다.
통계 적재 쿼리: INSERT … SELECT … ON DUPLICATE KEY UPDATE
통계는 Spring Data JPA의 네이티브 쿼리를 사용해 한 번에 적재합니다.

v2_orders와v1_members조인o.member_id = m.id조건으로 주문과 회원 정보를 조인합니다.
- 회원별 GROUP BY 집계
group by m.id, m.email로 각 회원에 대해,- 주문 수(
count(o.id)) - 총 금액(
sum(o.total_amount)) - 평균 금액(
avg(o.total_amount)) - 마지막 주문 일자(
max(o.order_date))
를 계산합니다.
- 주문 수(
- 집계 결과를
v2_order_stats에 INSERTmember_id를 PK로 사용하는 테이블에 통계 데이터를 적재합니다.
- 이미 존재하는 회원 통계는 UPDATE
on duplicate key update ...구문을 사용해 동일한member_id가 이미 존재할 경우,
기존 row를 새로 계산된 통계 값으로 갱신합니다.- 즉, “없으면 INSERT, 있으면 UPDATE” 형태의 삽입과 수정을 한 번에 처리합니다.
이렇게 해서 refreshOrderStats() 메서드를 한 번 호출하면, 모든 회원에 대한 최신 주문 통계 스냅샷이 한 번에 갱신됩니다.
배치 스케줄링: 3분마다 통계 재계산
서비스 계층에서는 위 쿼리를 스케줄링 배치 작업으로 수행합니다.
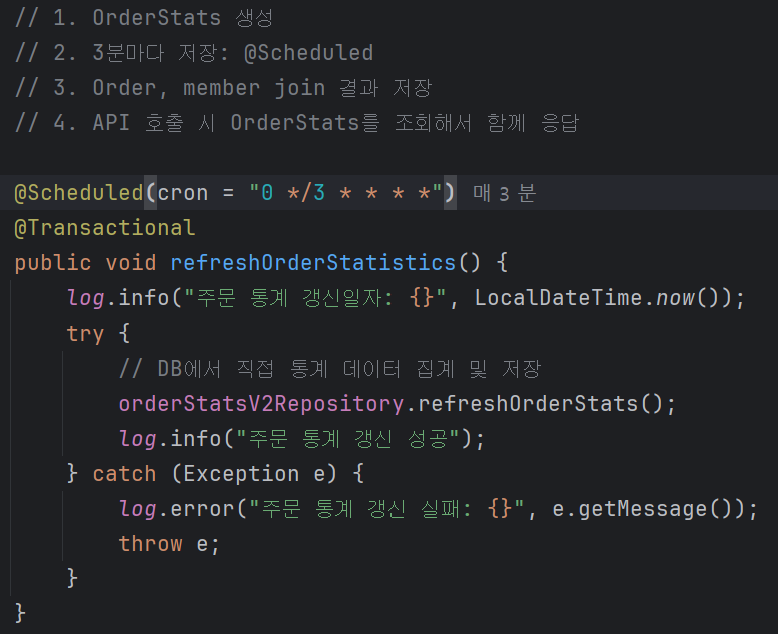
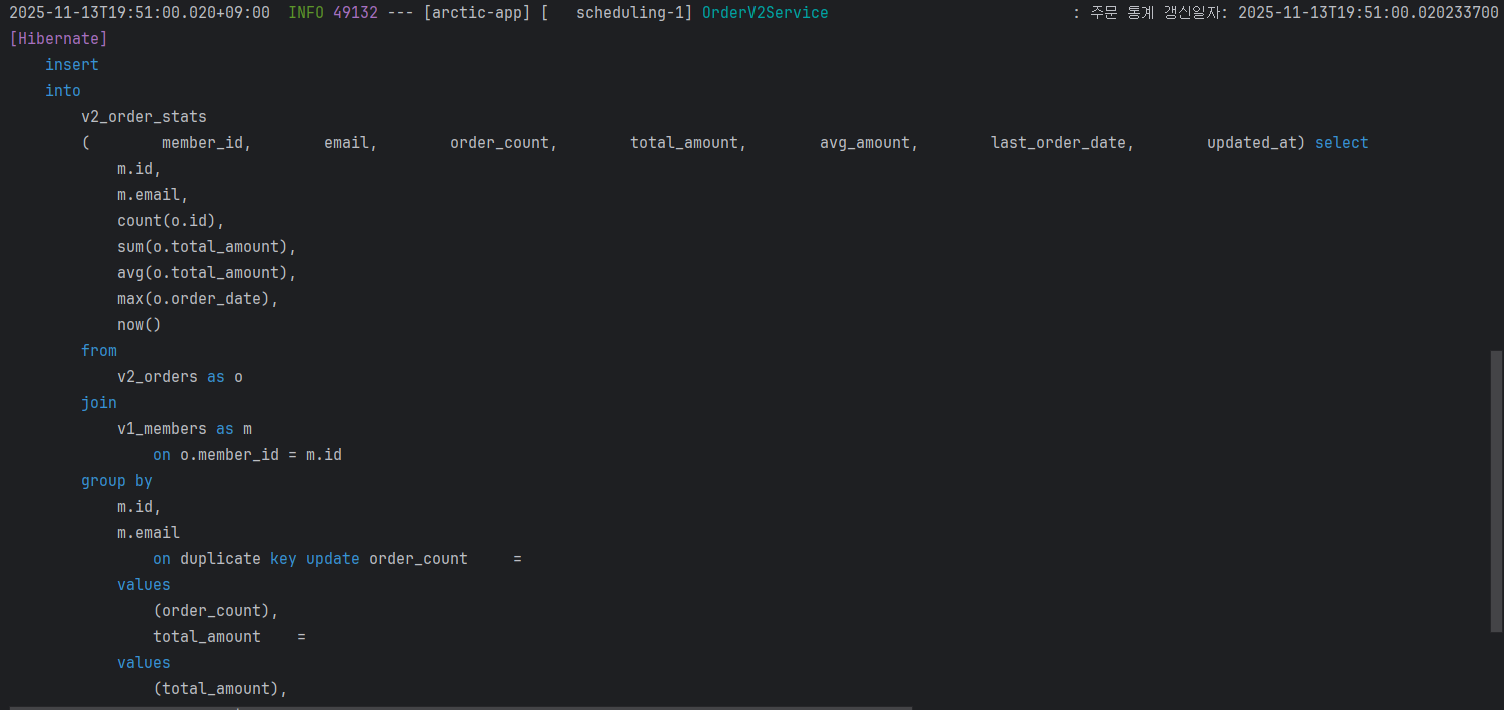

- 애플리케이션이 살아 있는 동안 3분마다
refreshOrderStatistics()메서드를 실행 - 메서드 내부에서는 앞에서 정의한 네이티브 통계 쿼리 한 번만 호출
- 트랜잭션 안에서 실행되므로, 통계 적재/갱신이 전부 성공하거나 전부 롤백되는 일관성이 보장
따라서 v1_orders 전체를 다시 집계하지 않고, 이미 계산된 v2_order_stats를 단순 조회해서 응답에 포함합니다.
아래와 같은 흐름으로 동작하게 됩니다.
- OrderStats는 Order 통계 데이터를 담아주기 위한 테이블
- 서버에서 주기적으로 회원의 Order 데이터 조회 후 OrderStats에 저장
- API 호출 시 OrderStats만 조회하면 되기 때문에 무거운 연산 작업이 불필요
이제 OrderStats 통계 테이블 조회로 별도의 복잡한 GROUP BY 연산 없이 3초 걸린 응답이 300ms으로 빠른 응답을 할 수 있습니다.
### 회원별 주문 통계
GET api/v2/orders/stats?minAmount=50000&page=0&size=20
Content-Type: application/json
현재 단일 테이블을 인덱스 없이 특정 컬럼을 기준으로 조회하고 있습니다. 따라서 Full Scan이 발생하는데, 지금처럼 조건절에 WHERE total_amount >= ?를 자주 사용하므로 total_amount 컬럼를 갖는 인덱스를 생성합니다. 따라서 단일 인덱스를 추가합니다.
ALTER TABLE v2_order_stats ADD INDEX idx_total_amount (total_amount);
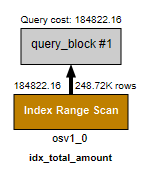
적용 후, 실행 계획은 type - range 입니다. Index Range Scan으로 필요한 구간만 검색하여 조회 속도가 더욱 빨라집니다.
300ms 에서 81ms까지 더 빨라지게 되었습니다. 배치 작업(스케줄링)을 통해 주기적으로 데이터를 집계 후 쿼리 시 즉시 조회라는 흐름으로 대량 통계 처리를 최적화했습니다.
보고 및 성과
최초 문제 상황
회원별 주문 통계 조회 시 대규모 GROUP BY 수행으로 전체 스캔으로 3초 이상의 긴 응답 시간이 발생했습니다.
실행 계획 결과
type - index: 99 만 건 인덱스 풀 스캔 발생으로 인한 쿼리 비용의 부담- Nested Loop 특성으로 인해 Inner Loop 비용 증가하여 전체 비용도 함께 증가
개선된 실행 방식
- OrderStats 집계 테이블 생성 후 주기적으로(배치) 집계 결과를 저장
- 회원별 주문 통계 조회 시 집계 테이블만 복잡한 쿼리 없이 조회
- 추가적인 인덱스(
total_amount)를 활용해서 조건 검색 속도를 향상
성능 개선 효과
- 미리 계산된 데이터는 실시간 계산에 따른 부하를 제거
- 응답 시간: 3.2초 -> 81ms
- 약간의 지연(3분 단위 갱신)이 허용된다면, 대규모 트래픽에서도 매우 안정적인 성능 보장을 기대
5. 추가: 복합 조건 주문 검색 시 주문 아이템 개수
복합 주문 검색 시 각 주문별로 주문 아이템(order_items) 조회를 합니다.
### 복합 조건 주문 검색 (최근 주문)
GET api/v1/orders/complex-search?startDate=2024-02-01T00:00:00&status=COMPLETED&minAmount=100000
Content-Type: application/json
여기에서 문제는 페이징으로 20 개의 응답한다면 주문 아이템 테이블에 조회도 20 번이 발생되는 문제가 있습니다.
이 문제는 DTO를 만들고 있는 로직에 의한 중복 조회 발생이었습니다.

order와 연관된 orderItems를 모두 가져와서 길이를 구합니다. 이 무거운 작업은 orderItems의 개수를 나타내기 위한 목적으로만 사용하고 있습니다. "주문 아이템 개수"만 필요한데, 매 번 실제 아이템 레코드 전부를 DB에서 불러오는 상황이에요. 불필요한 데이터 조회로 인해 불필요한 20 번의 쿼리가 발생하게 된 것 입니다.
이 문제를 해결하기 위해 반정규화를 수행할 수 있습니다. 지금처럼 정규화된 구조에서는 각 주문에 연결된 아이템 테이블을 조회해서 아이템 수를 계산하는 수 밖에 없습니다. 결국 불필요한 쿼리 증가로 이어지는 문제가 지금처럼 발생하게 됩니다. 따라서 이러한 연관 모델의 레코드 개수는 개별 상품 컬럼에 포함하여 Order만 보더라도 OrderItems의 개수를 알 수 있습니다.
그러나 반정규화는 장단점이 매우 뚜렷합니다.
장점: 속도 향상
- 주문 목록을 조회할 때 별도 조인이나 추가 쿼리 없이 개수를 확인 가능
- 불필요한 데이터 로드(N+1 문제 등)가 사라져 쿼리 수도 줄고, 전체 응답 시간 단축
단점: 정합성 관리
- 데이터가 여러 곳에 분산(중복)되어 있으므로, 수정 시 여러 테이블을 동기화해야 함
- 주문 아이템 개수가 바뀌면, 비정규화된
total_items값도 갱신해야 함 - 잘못 관리하면 데이터 불일치가 발생할 수 있어, 추가 로직(트리거, 배치 작업 등)이 필요
@Entity
@Table(name = "v2_orders")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class OrderV2 extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member;
@Column(unique = true)
private String orderNumber;
@Enumerated(EnumType.STRING)
private OrderStatus status;
private LocalDateTime orderDate;
private int totalAmount;
private int totalItems; // 반정규화된 필드 추가
}
v2_orders 테이블에 쿼리를 통해 마이그레이션을 합니다.
기존 v1_orders의 데이터와 v1_order_items로부터 각 주문별 아이템 개수를 하나의 쿼리로 v2_orders에 이관하는 작업을 진행합니다.
`v2_orders` 마이그레이션
INSERT INTO v2_orders(
id,
member_id,
order_number,
status,
order_date,
total_amount,
total_items,
created_at,
updated_at
)
SELECT
o.id,
o.member_id,
o.order_number,
o.status,
o.order_date,
o.total_amount,
(SELECT COUNT(*) FROM v1_order_items oi WHERE oi.order_id = o.id) as total_items,
o.created_at,
o.updated_at
FROM v1_orders o;더이상 order_items 테이블을 반복적으로 조회하는 쿼리를 수행하지 않아도 됩니다. 기존 order는 연관된 orderItems를 모두 가져와서 길이를 구해야만 했는데, 앞으로는 v2_orders의 total_items 컬럼을 조회하기만 하면 됩니다. 덕분에 쿼리 수도 줄어들고, 응답 속도도 상당히 향상되는 것을 기대할 수 있습니다.

가장 큰 단점은 정합성입니다. v2_orders의 total_items 개수를 마추기 위한 추가 로직이 반드시 필요합니다. 주문한 상품의 아이템 개수가 변경되는 경우는 항상 total_items의 값도 함께 변경이 되어야만 합니다.
보고 및 성과
최초 문제 상황
복합 조건 주문 검색 API에서 페이지당 20건을 응답할 때, 각 주문별로 연관된 주문 아이템(order_items)을 추가로 조회하는 문제가 있었습니다. DTO 변환 과정에서 order.getOrderItems().size() 로 “주문 아이템 개수”를 계산하면서, 단순히 개수만 필요함에도 불구하고 매번 실제 아이템 레코드 전체를 DB에서 조회하게 되었습니다.
- 주문 목록 조회 1번 쿼리 + 주문당 아이템 조회 N번 쿼리 → 1 + N 형태의 중복 쿼리
- 페이지당 20건이면
order_items테이블 조회도 20번 추가 발생 - 불필요한 데이터 로드와 네트워크 왕복으로 응답 시간이 증가하고, DB 부하도 커지는 상황
원인 분석
OrderResponse변환 로직에서 주문 아이템 개수를 구하기 위해order.getOrderItems().size()를 사용
→ JPA 입장에서는 Order 목록 조회 이후, 각 Order마다 연관된 OrderItems를 Lazy 로딩
→ “아이템 개수”만 필요하지만, 실제로는 각 주문별 모든 아이템 row 를 읽는 비효율 발생- 구조적으로 정규화된 모델(v1_orders + v1_order_items) 이라 “아이템 개수”를 알기 위해서는 항상
order_items에 접근해야 함 - 이로 인해 페이지 크기만큼 추가 쿼리가 선형적으로 증가하는 N+1 패턴 이 발생
개선된 실행 방식
- 주문 아이템 개수를 빠르게 제공하기 위해 반정규화 컬럼
total_items를 도입한 새로운 테이블v2_orders를 설계 OrderV2엔티티에totalItems필드를 추가하여,
주문 한 건만 조회해도 해당 주문의 아이템 개수를 바로 알 수 있도록 변경- 기존 데이터를
v2_orders로 마이그레이션 - 기존 v1_orders 와 v1_order_items 를 이용해, 주문별 아이템 개수를 한 번에 계산하여 v2_orders.total_items 에 적재
- API 레이어 수정
- DTO 변환 시
order.getOrderItems().size()대신order.getTotalItems()값을 그대로 사용 - 복합 검색 쿼리는
v2_orders만 조회하고, 추가적인order_items조회는 수행하지 않도록 변경 - 결과적으로 주문 목록 조회 = 단일 쿼리 1번으로 수렴
- DTO 변환 시
성능 개선 효과
- 쿼리 수 감소
- 기존: 주문 목록 조회 1번 + 주문별 아이템 조회 N번 → 페이지당 21번(1+20) 수준의 쿼리 발생
- 개선: 주문 목록 조회 1번 +
total_items컬럼 직접 사용 → 페이지당 쿼리 1번(20 -> 1 쿼리 감소)
- 불필요한 데이터 로드 제거
- 더 이상 각 주문의 모든
order_items레코드를 읽지 않고, 정수 컬럼 하나(total_items)만 읽으면 됨 - 네트워크 트래픽, 디스크 I/O, 애플리케이션 메모리 사용량 모두 감소
- 더 이상 각 주문의 모든
- 응답 지연 가능성 감소
- 페이지 크기가 커질수록 기하급수적으로 늘어날 수 있던 N+1 쿼리가 제거되어,
복합 조건 검색 + 페이징 상황에서도 안정적인 응답 시간을 기대할 수 있음
- 페이지 크기가 커질수록 기하급수적으로 늘어날 수 있던 N+1 쿼리가 제거되어,
- 트레이드오프 및 관리 전략
가장 큰 단점은 정합성 관리 부담입니다.
주문 아이템이 추가/삭제/변경될 때마다 v2_orders.total_items 값도 함께 갱신되어야 합니다. 주문 생성/변경 서비스 로직에서 total_items 를 함께 증가/감소 시키거나 트리거, 배치 검증 작업 등을 통해 정합성을 주기적으로 체크하는 보완 로직이 필요합니다.
그럼에도 불구하고, “조회가 훨씬 많고, 아이템 개수는 읽기 위주로 자주 사용된다”는 전제에서는 반정규화로 읽기 성능을 극대화하고, 쓰기 시점에만 정합성을 관리하는 전략이 유효한 선택이 됩니다.
느낀점
이번 성능 개선을 하면서 가장 크게 느낀 점은, “느리다”라고 느끼는 것만으로는 아무것도 바꿀 수 없고 로그와 실행 계획으로 병목을 숫자로 보는 게 출발점이라는 거였습니다. 주문 검색과 통계 조회가 3초 이상 걸리던 원인은 막연한 “데이터가 많아서”가 아니라, 인덱스가 안 맞는 풀 스캔, 실시간 GROUP BY, 그리고 N+1 쿼리 패턴처럼 아주 구체적인 문제들이었습니다.
또 하나 배운 것은 정규화만으로는 실제 트래픽을 버티기 어렵다는 점입니다. 통계는 집계 테이블로 분리해 배치로 미리 계산하고, 주문 아이템 개수는 total_items 컬럼으로 반정규화해서 조회 비용을 줄였습니다. 정합성을 관리해야 하는 부담이 생겼지만, 읽기 성능이 크게 올라가는 것을 보며 “언제 정규화를 깨도 되는지”에 대한 감각을 조금 얻었습니다.
기능을 만들 때 지켜봐야 할 네 가지 원칙을 세워봤습니다.
- 느리면 먼저 측정하고 EXPLAIN을 확인하기
- 자주 쓰는 조건과 정렬을 기준으로 인덱스를 함께 설계하기
- 실시간 계산이 필요한 데이터와 배치로 처리할 수 있는 데이터를 분리하기
- N+1이나 과도한 JOIN이 보이면 반정규화도 과감히 검토하기
'💭Retrospective' 카테고리의 다른 글
| 이미지 로딩 속도와 크기 70% 단축: WebP 변환부터 Redis 프리업로드로 URL을 보증하기 (0) | 2026.01.10 |
|---|---|
| 서평단: 그림으로 이해하는 도커와 쿠버네티스 (0) | 2026.01.09 |
| 서평단: Do it! HTML+CSS 웹 표준의 정석 탄탄한 웹 기본기를 위한 교과서 | 개정판 3 판 (0) | 2025.12.17 |
| 모임 목록 조회 API 트러블슈팅: 커서 기반 페이징과 N+1을 설계 구조로 해결하기 (0) | 2025.12.16 |
| 마틴 파울러가 소개하는 소프트웨어 아키텍처 (1) | 2025.11.25 |